Оновлення версії OKD з 4.11 до 4.12
Стаття описує процедуру оновлення версії OKD з 4.11 до 4.12 на платформах AWS та vSphere.
Розгорнути або згорнути список4.11.0-0.okd-2022-07-29-154152 ↓ 4.11.0-0.okd-2022-08-20-022919 ↓ 4.11.0-0.okd-2022-10-28-153352 ↓ 4.11.0-0.okd-2022-12-02-145640 ↓ 4.12.0-0.okd-2023-03-18-084815 ↓ 4.12.0-0.okd-2023-04-16-041331 |
Не рекомендовано оновлювати OKD на версію 4.11.0-0.okd-2023-01-14-152430 через наявний баг із працездатністю компонента Ceph. Дотримуйтеся рекомендованої послідовності оновлення.
|
|
|
Ви можете зупинити процес оновлення OKD та продовжити у будь-який зручний час. Головною умовою для зупинки процесу є кластер, який не знаходиться у процесі оновлення OKD або у процесі заміни |
1. Передумови
Для успішного проведення описаної процедури оновлення мають бути виконані наступні умови:
-
OKD-кластер версії
4.11або вище. -
Версія Платформи на кластері —
1.9.7або вище (див. детальніше — Вимоги до OKD-кластерів щодо інсталювання Платформи). -
Локально встановлений інструмент
oc cliверсії4.12або вище. -
Для інфраструктури AWS:
-
Наявний IAM-користувач із доступом до сервісу EC2.
-
Користувач має права на увімкнення та вимкнення вузлів (нод).
-
-
Для інфраструктури vSphere:
-
Наявний доступ до vSphere Client.
-
Наявний доступ до кожного вузла (ноди) кластера за допомогою SSH ключа.
-
-
Локально встановлений інструмент
jqдля роботи через термінал. -
Роль
cluster-adminна OKD-кластері. -
Ознайомлення з процесом оновлення з офіційного джерела: Офіційна документація оновлення OKD.
У випадку використання інфраструктури vSphere, обов’язково перевірте доступ по SSH до всіх вузлів кластера перед початком оновлення. Не розпочинайте процес оновлення OKD, якщо доступ по SSH не налаштований. Варто зазначити, що доступ до вузлів за командою oc debug node/{node_name} не буде доступний під час оновлення!
|
2. Підготовчі дії перед оновленням
-
Перед початком процесу оновлення, важливо переконатися, що ваш OKD кластер працює без помилок:
-
Відрийте вебінтерфейс OKD.
-
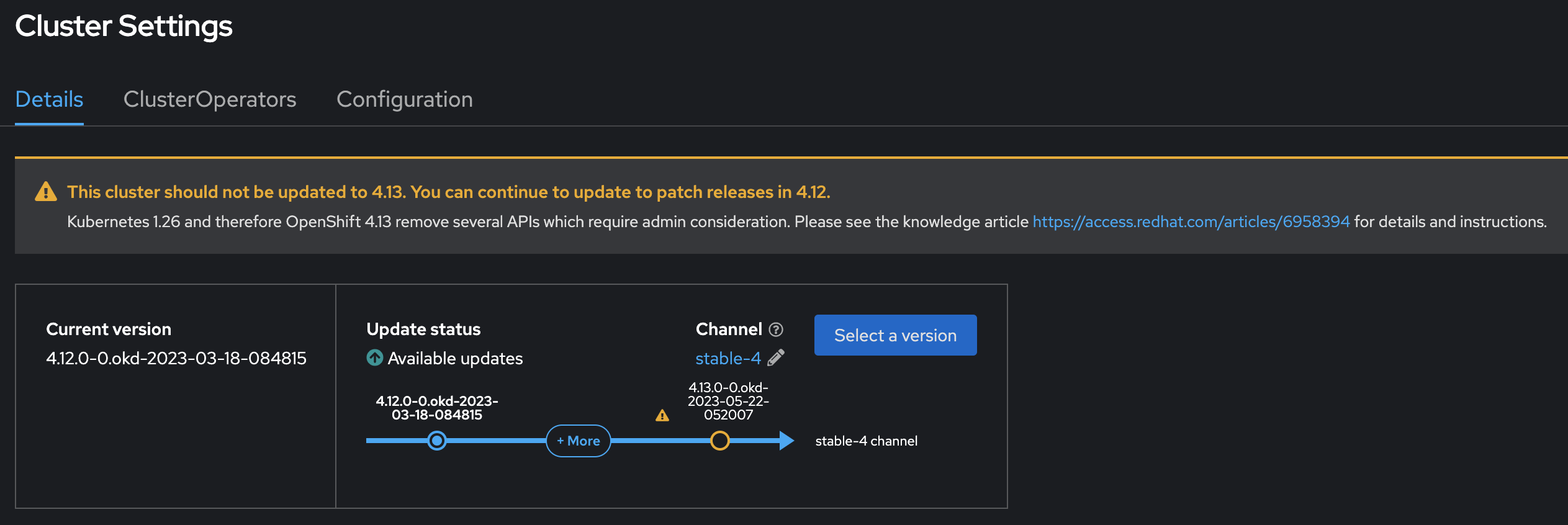
Перейдіть до розділу Administration > Cluster Settings.
-
Уважно перевірте стан кластера. Переконайтеся, що інформаційна панель стану кластера не показує жодних попереджень (
WARNING) або помилок (ERROR). Це забезпечить, що кластер знаходиться у готовності до оновлення.
У випадку, якщо під час перевірки стану кластера з’являється повідомлення:
Cluster operator machine-config should not be upgraded between minor versions: PoolUpdating: One or more machine config pools are updating, please see oc get mcp for further details
та у ресурсі MachineConfigPool із назвою master спостерігається помилка:
Node ip-*-*-*-*.eu-central-1.compute.internal is reporting: "machineconfig.machineconfiguration.openshift.io \"rendered-master-***\" not found"
в такому випадку рекомендується виконати наступну команду в
oc cliта дочекатися перезапуску всіх мастер-нод кластера:$ oc delete mc 99-okd-master-disable-mitigations 99-master-okd-extensions -
-
Перевірте, чи встановлено параметр Upstream configuration у значення
https://amd64.origin.releases.ci.openshift.org/graph. Це вказує на офіційне джерело оновлень.
-
У розділі Administration > Cluster Settings" перейдіть на вкладку ClusterOperators.
Перевірте, що жоден з операторів не перебуває у стані
Updating.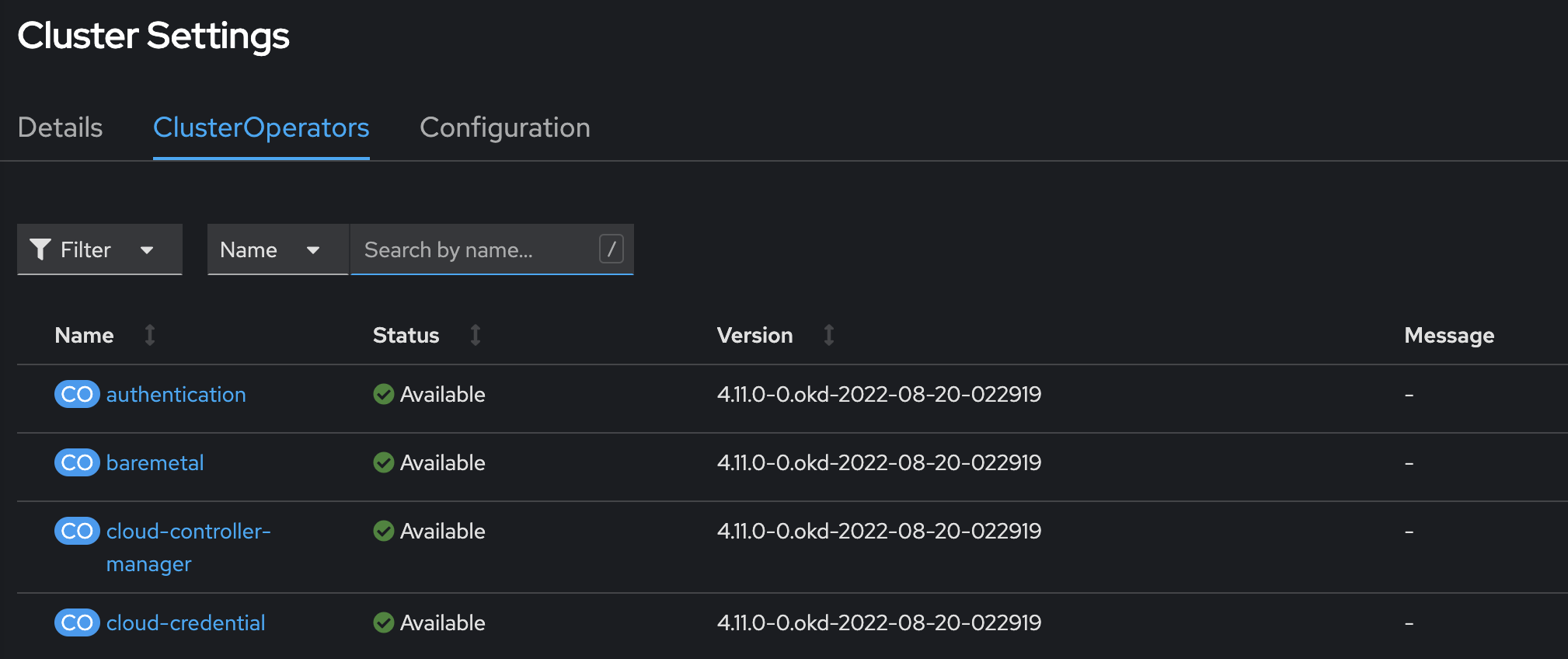
3. Процедура оновлення
-
Спочатку переконайтеся, що ваш кластер готовий до цього процесу видалення Kubernetes API в OKD 4.12. Для цього виконайте наступну команду через термінал:
okd$ oc -n openshift-config patch cm admin-acks --patch '{"data":{"ack-4.11-kube-1.25-api-removals-in-4.12":"true"}}' --type=merge -
Призупиніть ресурси MachineHealthCheck перед оновленням кластера. Це дозволить уникнути перезавантаження нод при оновленні.
pause$ oc get machinehealthcheck -n openshift-machine-api $ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused="" -
Вимкніть усі реєстри. Для вимкнення усіх реєстрів використовуйте наступний процес, який може бути автоматизований за допомогою запропонованого bash-скрипту. Скрипт виконує наступні дії для кожного реєстру (codebase):
-
Перевірка стану Istio.
-
Патчінг ресурсу IstioControlPlane для вимкнення роботи Istio для реєстру.
-
Анотування ресурсу MachineSet реєстру з поточною кількістю реплік.
-
Анотування ресурсів Machine для MachineSet реєстру для подальшого їх видалення.
-
Позначення кожної ноди реєстру як
Unscheduled. -
Видалення усіх подів з ноди для подальшого видалення ноди.
-
Перехід усіх CronJob реєстру в стан паузи.
-
Виконання scale MachineSet реєстру до 0 реплік.
Цей процес забезпечує безпечне та ефективне вимкнення реєстрів, готуючи їх до подальшого видалення чи оновлення.
Скрипт registries_turn_off.sh
#!/usr/bin/env bash CHECK-HEALTH-OF-ISTIO() { echo "Checking if IstioOperator resource is healthy..." isIstioHealthy=$(oc get -n istio-system IstioOperator istiocontrolplane -o jsonpath='{.status.status}') counterForCheckingIstio=3 while [ ${counterForCheckingIstio} -gt 0 ]; do if [[ ${isIstioHealthy} == "HEALTHY" ]]; then echo "IstioOperator resource is healthy" break else counterForCheckingIstio=$[ $counterForCheckingIstio - 1 ] if [ ${counterForCheckingIstio} -eq 0 ]; then echo "IstioOperator resource with name istiocontrolplane in namespace istio-system is not healthy!" echo "Fix it manually and try again later!" exit 1 else echo "IstioOperator resource with name istiocontrolplane in namespace istio-system is not healthy!" echo "Sleeping for 30 seconds" sleep 30 echo "Trying again..." fi fi done } PATCH-ISTIO() { CHECK-HEALTH-OF-ISTIO echo "Turning off Istio ingress gateway in registry ${1}" indexOfIstioIngressGateways=$(oc get -n istio-system IstioOperator istiocontrolplane -o json | jq '.spec.components.ingressGateways | map(.namespace == "'${1}'") | index(true)') oc patch -n istio-system IstioOperator istiocontrolplane --type json -p '[{"op": "replace", "path": "/spec/components/ingressGateways/'${indexOfIstioIngressGateways}'/enabled", "value": false}]' } CHECK-HEALTH-OF-ISTIO for registry in $(oc get codebases -n control-plane --no-headers -o custom-columns=":metadata.name" --field-selector=metadata.name!=cluster-mgmt); do registryMachineSet=$(oc get -n openshift-machine-api MachineSet -o=jsonpath='{.items[?(@.metadata.annotations.meta\.helm\.sh/release-namespace=="'"${registry}"'")].metadata.name}') registryMachineSetReplicas=$(oc get -n openshift-machine-api MachineSet ${registryMachineSet} -o jsonpath='{.spec.replicas}') if [ $registryMachineSetReplicas -ne 0 ]; then echo "Turn off registry ${registryMachineSet}" PATCH-ISTIO "${registry}" isAnnotationPresent=$(oc get -n openshift-machine-api MachineSet ${registryMachineSet} -o=jsonpath='{.metadata.annotations.registryMachineSetReplicas}') if [ ${isAnnotationPresent} ]; then echo "Annotation [registryMachineSetReplicas] is already present in MachineSet ${registryMachineSet}" else echo "Annotate MachineSet ${registryMachineSet} before scale down" oc annotate -n openshift-machine-api MachineSet ${registryMachineSet} registryMachineSetReplicas=${registryMachineSetReplicas} fi for machine in $(oc get -n openshift-machine-api Machines -l machine.openshift.io/cluster-api-machineset=${registryMachineSet} -o jsonpath='{range .items[*].metadata}{.name}{"\n"}{end}'); do echo "Annotate Machine ${machine} before deletion" oc annotate -n openshift-machine-api machine/${machine} machine.openshift.io/cluster-api-delete-machine="true" oc annotate -n openshift-machine-api machine/${machine} machine.openshift.io/exclude-node-draining="true" done for node in $(oc get -n openshift-machine-api Nodes -l node=${registry} -o jsonpath='{range .items[*].metadata}{.name}{"\n"}{end}'); do echo "Cordon Node ${node}" oc adm cordon ${node} oc delete -n ${registry} pods --all --force --grace-period=0 echo "Drain Node ${node}" oc adm drain ${node} --ignore-daemonsets --force --grace-period=0 --delete-emptydir-data done for cronjob in $(oc get -n velero CronJobs -o jsonpath='{range .items[*].metadata}{.name}{"\n"}{end}' | grep ${registry}); do echo "Suspend CronJob ${cronjob}" oc patch -n velero CronJobs ${cronjob} -p '{"spec":{"suspend":true}}' done oc scale -n openshift-machine-api --replicas=0 MachineSet ${registryMachineSet} else echo "Registry ${registryMachineSet} is disabled" fi done -
-
Змініть конфігурацію розгортання (patch deployment)
istiodу вашому Kubernetes-кластері. Для цього запустіть команду, яка зменшить кількість реплік до нуля, що дозволить уникнути переривань під час оновлення кластера. Команда, яку ви можете використати вoc(OpenShift CLI), виглядає так:patch deployment istiod$ oc scale deployment istiod --replicas=0 -n istio-systemЦя команда встановлює кількість реплік розгортання (deployment)
istiodяк0у просторі іменistio-system, тимчасово зупиняючи його. -
Оновіть ресурс istioOperator з ім’ям istiocontrolplane у просторі імен
istio-systems. Для цього внесіть зміни до конфігурації, встановивши полеenabledу значенняfalseдля специфічного блокуistio-ingressgateway-control-plane-main. Це можна зробити шляхом редагування YAML-файлу конфігурації.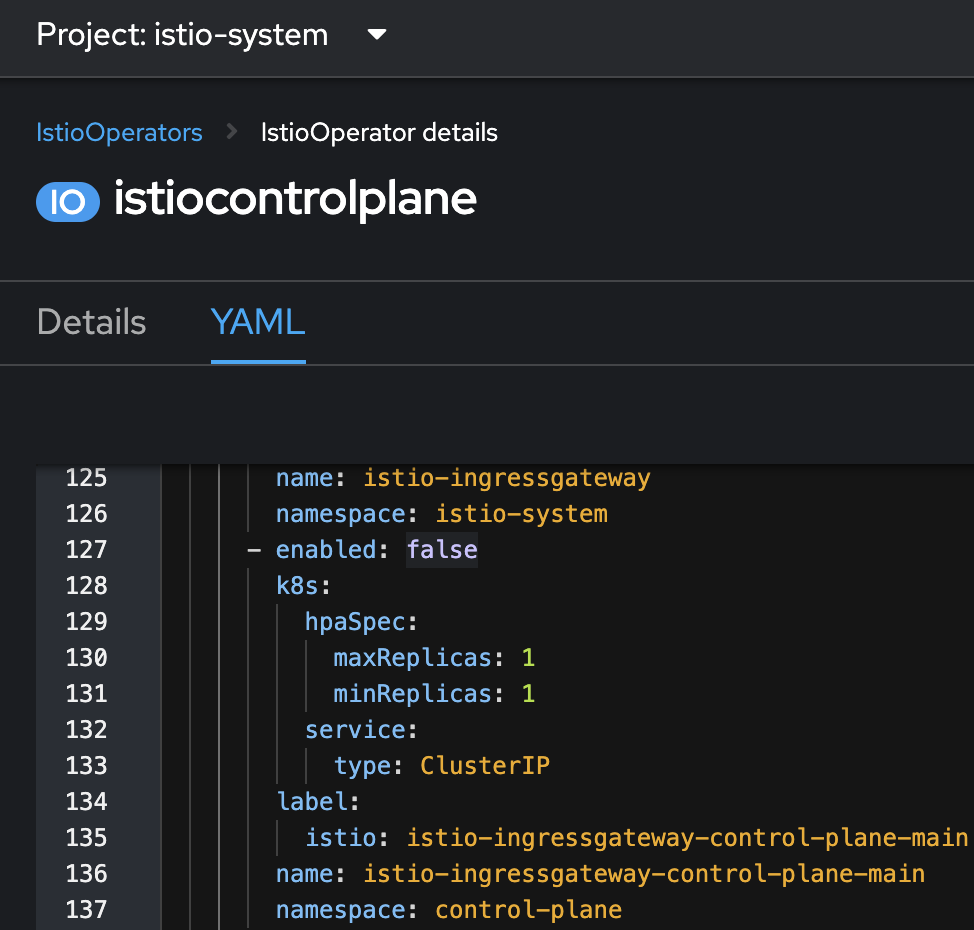
-
Збільште кількість реплік
worker-нод із 3 до 4 у вашому OKD кластері. Для цього оновіть конфігурацію відповідного MachineSet. Це дозволить запобігти можливим проблемам із нестачею ресурсів під час оновлення OKD.Перед переходом до наступного кроку важливо дочекатися, коли нова worker-нода повністю підійметься та стане активною у кластері.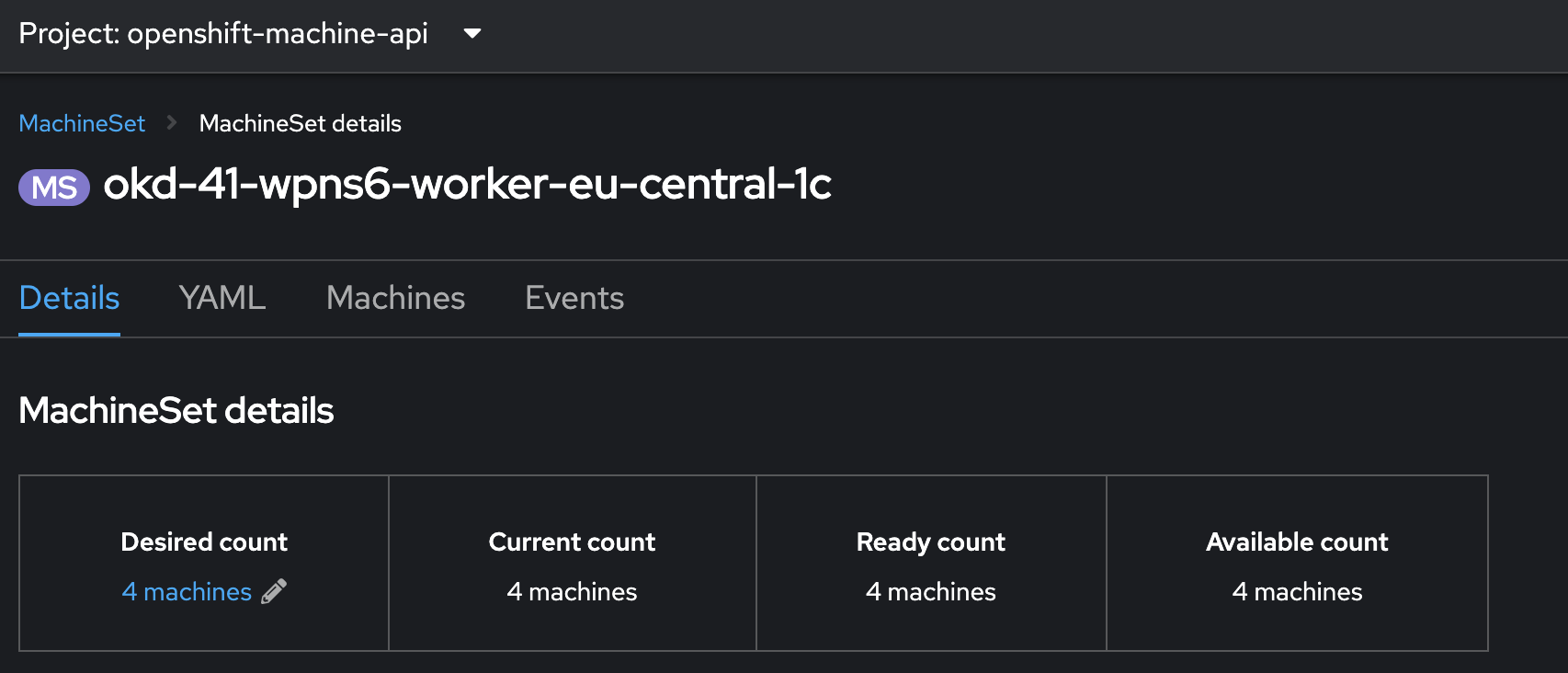
-
Перед оновленням OKD слід враховувати, що під час процесу оновлення воркер ноди можуть зависати або не оновлюватися. Якщо ви помічаєте таку поведінку, рекомендується видалити ресурс Machine для проблемної ноди. Цей ресурс зазвичай знаходиться у розділі Compute в інтерфейсі керування кластером.
Також під час оновлення OKD можуть з’являтися попередження та помилки. В більшості випадків це вважається нормальною поведінкою, яка згодом самостійно вирішується. 
-
-
Оновіть OKD до версії
4.11.0-0.okd-2022-08-20-022919.Для цього перейдіть до розділу Administration > Cluster Settings у вебінтерфейсі OKD. Далі оберіть потрібну версію зі списку доступних (поле Select new version).
Після вибору версії, дочекайтеся завершення процесу оновлення та пропозиції оновитися далі.
Якщо ваша поточна версія OKD вже відповідає 4.11.0-0.okd-2022-08-20-022919, цей крок можна пропустити.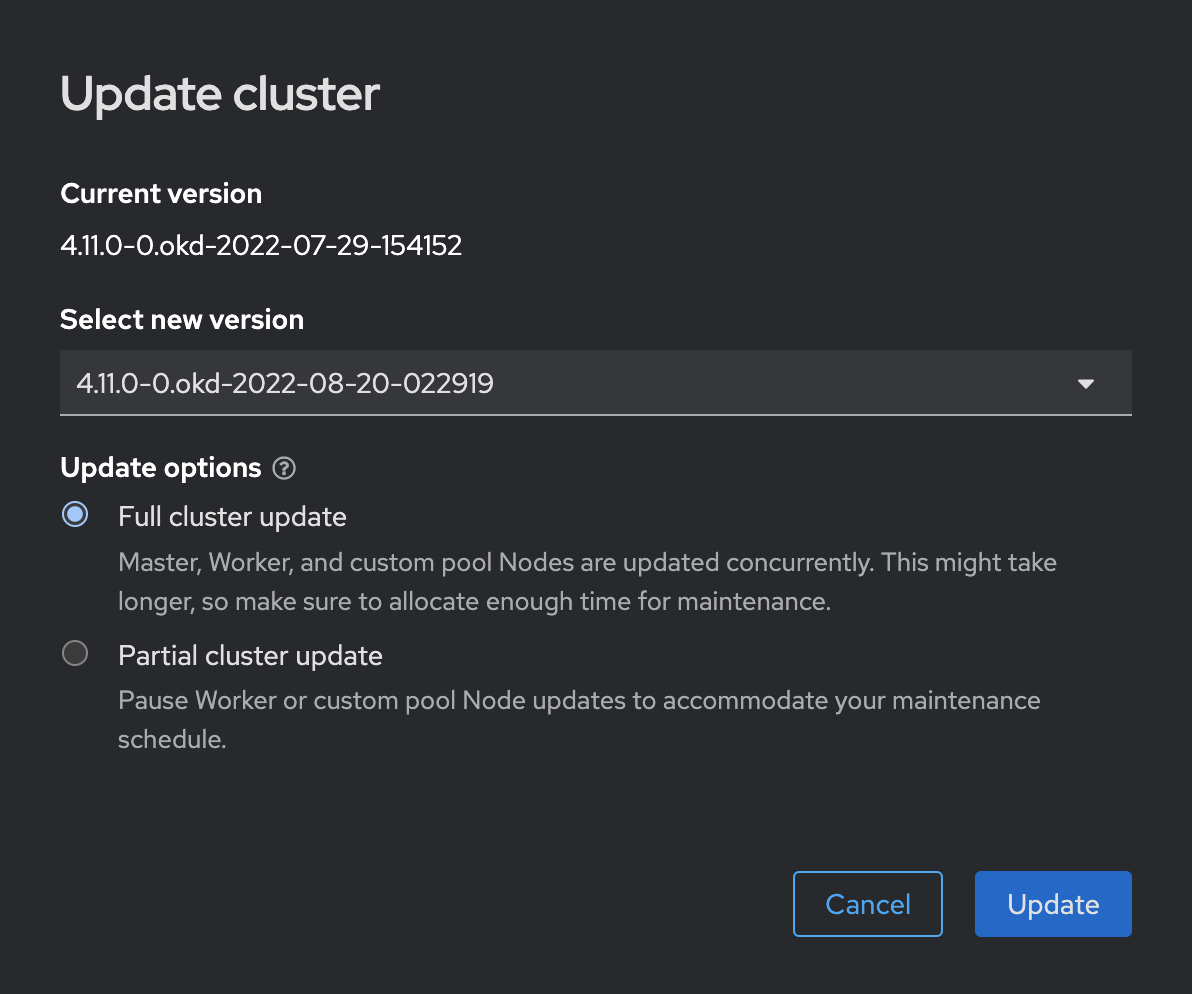
-
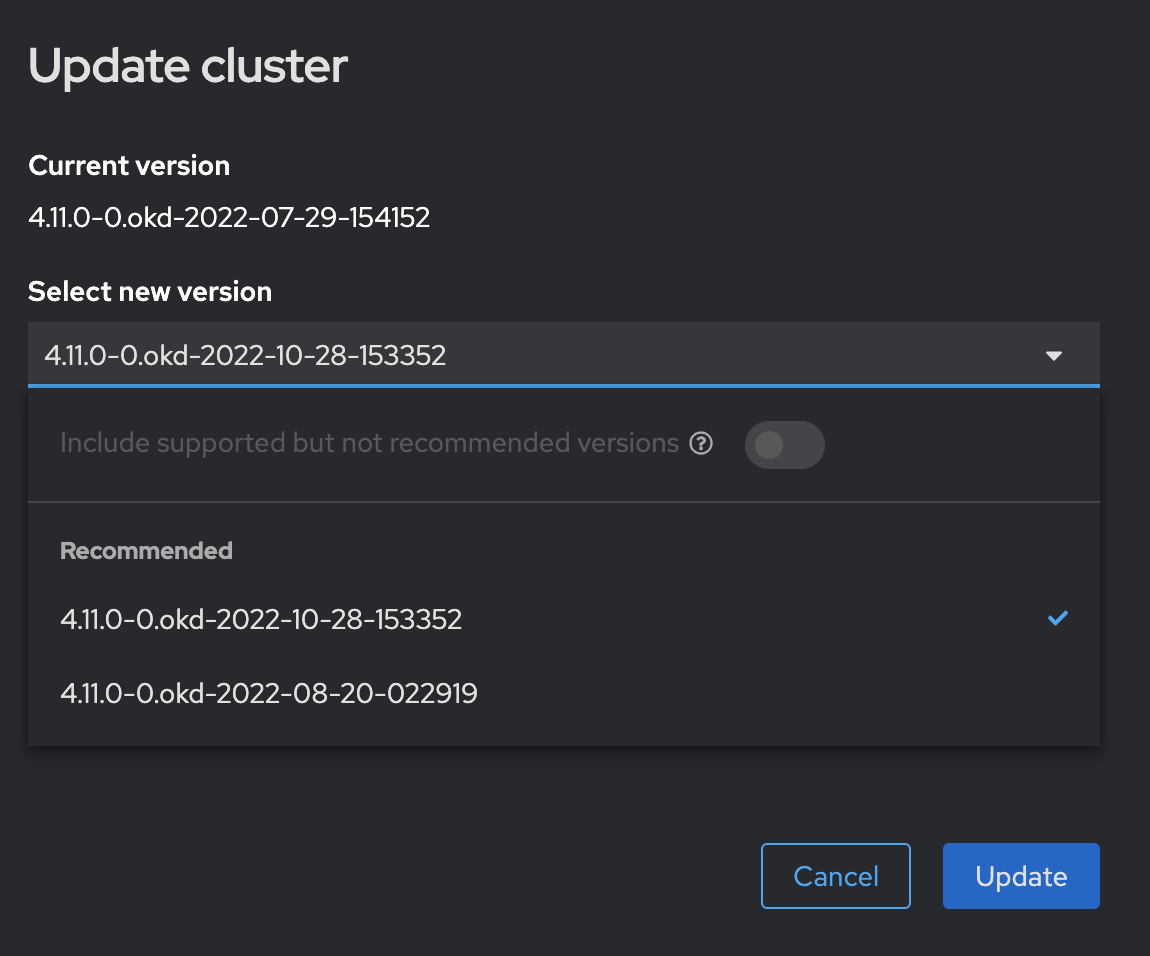
Оновіть OKD до версії
4.11.0-0.okd-2022-10-28-153352.Для цього перейдіть до розділу Administration > Cluster Settings у вебінтерфейсі OKD. Далі оберіть потрібну версію зі списку доступних (поле Select new version).
Після вибору версії, дочекайтеся завершення процесу оновлення та пропозиції оновитися далі.
-
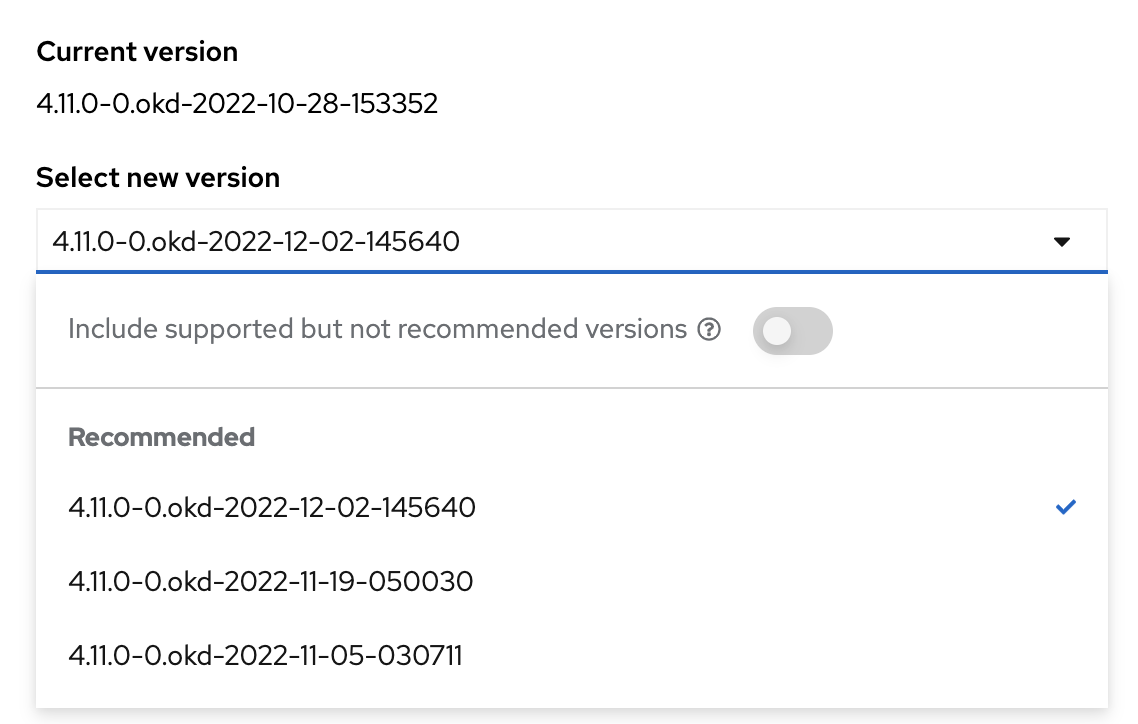
Оновіть OKD до версії
4.11.0-0.okd-2022-12-02-145640.Для цього перейдіть до розділу Administration > Cluster Settings у вебінтерфейсі OKD. Далі оберіть потрібну версію зі списку доступних (поле Select new version).
Після вибору версії, дочекайтеся завершення процесу оновлення та пропозиції оновитися далі.
-
На інфраструктурі AWS через баг OKD (https://github.com/okd-project/okd/issues/1657), оновлення не може бути продовжене до версії 4.12. Для розв’язання цієї проблеми необхідно перевести всі
master-ноди на новий AMI. Це можна зробити за документацією, шляхом заміниmaster-ів.Процедуру заміни AMI потрібно виконати для кожної master-ноди по черзі. Перед заміною нода має бути вимкнена!Кроки виконання заміни AMI для мастер ноди:
-
Вимкніть мастер-ноду, яку плануєте замінити. Для цього, для AWS-інфраструктури, перейдіть до AWS UI та у сервісі EC2 виконайте для обраного екземпляра дію
Stop. -
Перевірте стан наявних etcd-подів. Усі поди мають бути зі статусом
Running.$ oc -n openshift-etcd get pods -l k8s-app=etcd Зображення 1. Результат виконання команди
Зображення 1. Результат виконання команди -
Під’єднайтеся до будь-якого etcd-поду, що не відповідає мастер-ноді, яку плануєте замінити. Це можна визначити за назвою etcd-поду.
$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal -
Перегляньте список etcd-учасників (members).
$ etcdctl member list -w table Зображення 2. Результат виконання команди
Зображення 2. Результат виконання команди -
Видаліть etcd-учасника, що відповідає мастер-ноді, яку плануєте видалити.
$ etcdctl member remove 6fc1e7c9db35841d -
Перевірте видалення etcd-учасника. Повинно залишитись 2 учасники.
$ etcdctl member list -w tableЦю команду рекомендовано запустити декілька разів, щоб упевнитись, що etcd не перестворює видаленого etcd-учасника знову. -
Виходимо з поди etcd та вимикаємо Quorum Guard для etcd.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}' -
Знайдіть секрети для мастер-ноди, яку ви плануєте видалити, та видаліть їх.
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internalПриклад видалення секретів для обраної ноди$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internal $ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internal $ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
Секрети можуть відновитися після видалення — це нормальна поведінка. -
Виводимо список машин.
$ oc get machines -n openshift-machine-api -o wide -
Збережіть конфігураційний файл мастер-ноди, яку ви плануєте видалити.
$ oc get machine clustername-8qw5l-master-0 -n openshift-machine-api -o yaml > new-master-machine.yaml -
Відредагуйте збережену конфігурацію у файлі new-master-machine.yaml. Редагування файлу конфігурації для заміни мастер ноди в OKD включає наступні кроки:
-
Замініть поле
.metadata.nameна нове. Рекомендується зберегти основну частину наявного імені старої машини, змінивши лише кінцевий номер на наступний доступний. Наприклад, зclustername-8qw5l-master-0наclustername-8qw5l-master-3. -
Видаліть поле
.status. -
Видаліть поле
.spec.providerID. -
Замініть значення у
.spec.providerSpec.value.ami.idна новий AMI ID. Наприклад:ami-0037cfd83bf77778c.
-
-
Видаліть машину мастер-ноди, яку ви планували замінити.
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-0Цей крок може зайняти до 20 секунд. -
Перевірте, що машину видалено.
$ oc get machines -n openshift-machine-api -o wideПісля видалення машини важливо зачекати 2-3 хвилини перед тим, як переходити до наступного кроку: Застосування файлу конфігурації нової машини (крок n). Недотримання цієї паузи може призвести до непередбачених наслідків, таких як проблеми з мережею на новій ноді тощо. Якщо виникають проблеми із запуском нової ноди, потрібно повторно виконати процес видалення, починаючи з кроку Вимкнення мастер-ноди.
-
Застосуйте файл конфігурації нової машини.
Зачекавши 2-3 хвилини з моменту видалення ноди, застосуйте новий файл конфігурації.
$ oc apply -f new-master-machine.yamlЯкщо при застосуванні файлу конфігурації нової машини команда
oc applyне відповідає, це може бути ознакою того, що кластер почав процес перезавантаження. У цьому випадку важливо дочекатися, коли кластер знову стане доступним, перш ніж повторно застосовувати файл конфігурації нової машини. -
Перевірте, що машина створюється та запускається нова нода.
$ oc get machines -n openshift-machine-api -o wide$ oc get nodesВажливо зауважити, що процес створення нової машини для кластера може зайняти декілька хвилин. Під час цього процесу ноди кластера будуть перезавантажуватися, що може призвести до тимчасової недоступності кластера. Врахуйте це, плануючи виконання робіт, щоб уникнути незапланованого переривання доступу до послуг. -
Щойно нова мастер-нода буде успішно піднята та інтегрована в кластер, увімкніть Quorum Guard для
etcd. Це гарантує, щоetcdзберігає кворум та продовжує працювати стабільно. Увімкнення Quorum Guard важливе для забезпечення цілісності та високої доступності кластера.$ oc patch etcd/cluster --type=merge -p '\{"spec": \{"unsupportedConfigOverrides": null}}' -
Зачекайте, поки підніметься новий etcd-под для нової ноди.
$ oc -n openshift-etcd get pods -l k8s-app=etcdНа цьому етапі можуть перезавантажуватися ноди кластера. Це нормальна поведінка. -
На послідовних кроках Перевірка стану наявних etcd-подів, З’єднайтеся із довільним etcd-подом та Перегляд списку etcd-учасників можна перевірити, чи присутня нова нода в etcd-кворумі.
-
Після успішної заміни ноди обов’язково дочекайтеся реконсиляції etcd. Це можна перевірити у ресурсі etcd за допомогою команди:
$ oc get etcd/cluster -oyamlОдним із ключових індикаторів успішної реконсиляції є однаковий revisionусіх нод. Це свідчить про те, що всі ноди синхронізовані та коректно працюють після заміни.
-
Перейдіть до розділу Administration > Cluster Settings > ClusterOperators у вебінтерфейсі управління OKD, щоб перевірити статус усіх операторів. Усі оператори мають бути у статусі
Active. Зверніть увагу, що операторkube-apiserverчасто має статусProgressing, оскільки він оновлюєrevisionнод. Це нормальний процес, і вам слід дочекатися, коли він змінить статус наActive, що свідчить про завершення оновлення та стабільність кластера.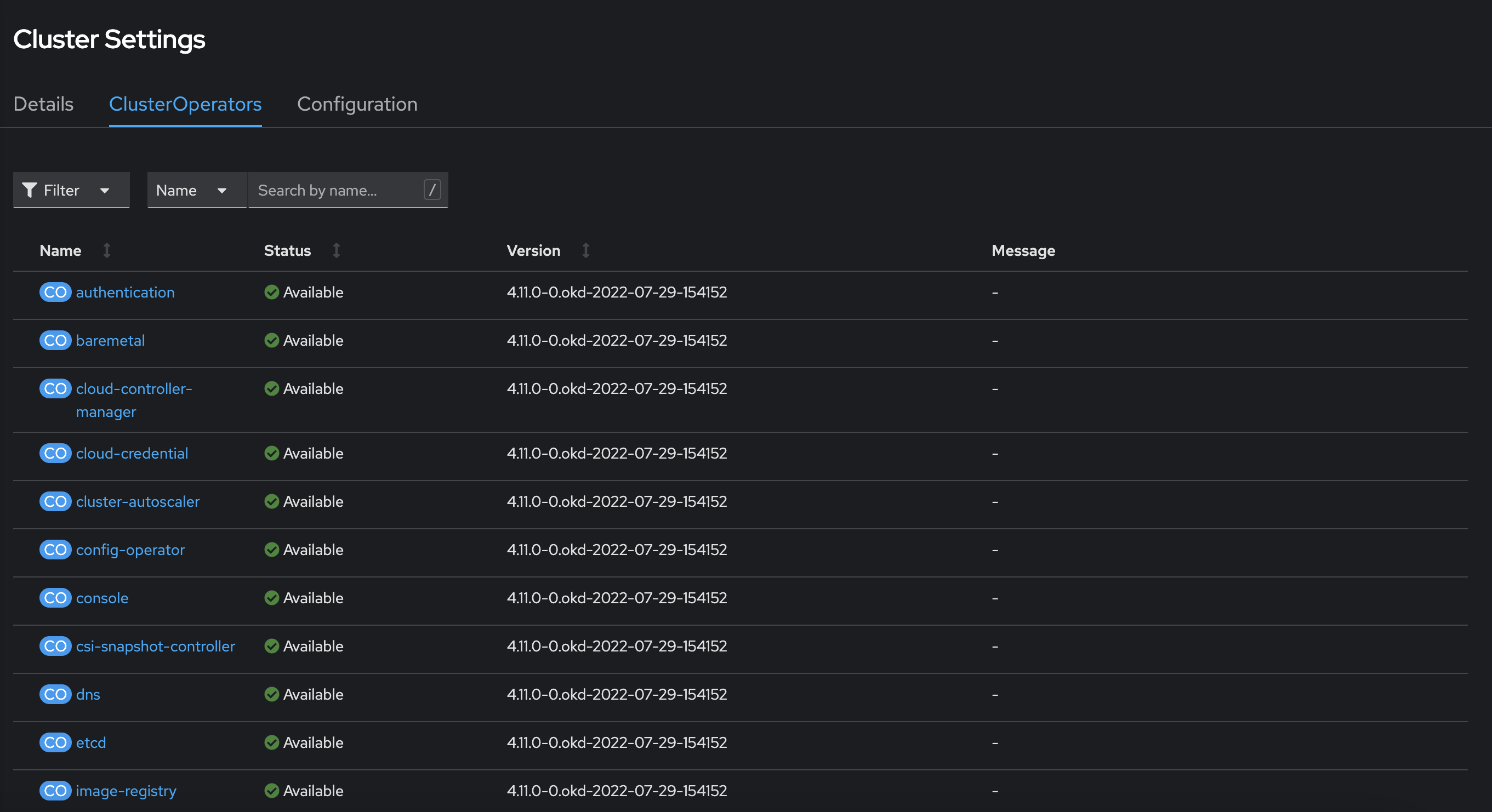
-
Після завершення реконсиляції
etcd(див. Реконсиляція etcd) та перевірки, що всі оператори мають статусActive(Статус операторів: Active), можна переходити до заміни AMI для наступної мастер-ноди, починаючи з кроку Вимкнення мастер-ноди.Важливо не ігнорувати ці кроки, оскільки завершена реконсиляція etcdі статусActiveусіх операторів є ключовими умовами для безпечної заміни AMI наступних мастер-нод. Недотримання цих вимог може привести до непередбачених проблем у кластері.
-
-
Після успішної заміни AMI на всіх мастер-нодах (для AWS інфраструктури, крок Заміна AMI для мастер-нод), оновіть OKD до версії
4.12.0-0.okd-2023-03-18-084815.Для цього перейдіть до розділу Administration > Cluster Settings у вебінтерфейсі OKD. Далі оберіть потрібну версію зі списку доступних (поле Select new version).
На інфраструктурі vSphere, під час оновлення OKD до версії
4.12.0-0.okd-2023-03-18-084815, може виникнути проблема, пов’язана з багом OKD, що стосується SELinux policies (див. детальніше: https://github.com/okd-project/okd/issues/1475) Цей баг може спричинити недоступність нод під час оновлення та статусNot Ready, який не змінюється з часом.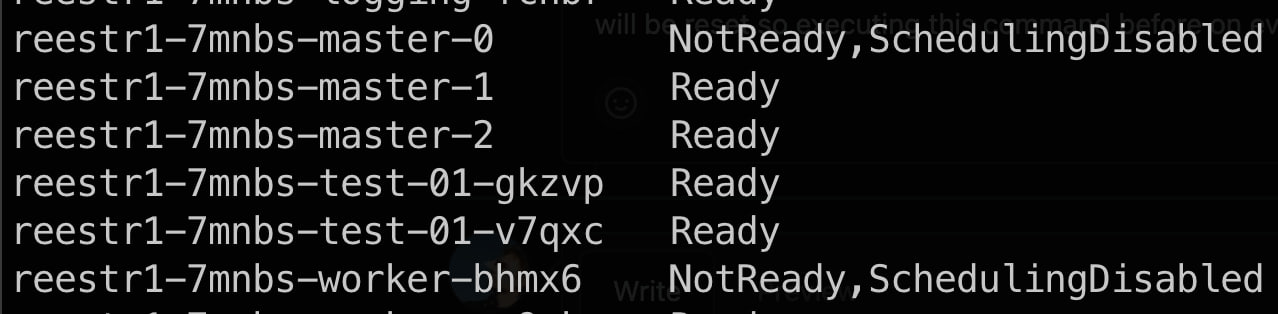 Зображення 3. Приклад проблемних нод під час оновлення при виконанні команди
Зображення 3. Приклад проблемних нод під час оновлення при виконанні командиoc get nodes-
Для розв’язання цієї проблеми під’єднайтеся до відповідної ноди зі статусом
Not Readyчерез SSH.IP-адресу ноди, яка перебуває у статусі
Not Ready, можна знайти за допомогою команди:$ oc get nodes -o wide. -
Після підключення до проблемної ноди через SSH, введіть наступну команду у терміналі цієї ноди для відновлення налаштувань контекстів безпеки всіх файлів та директорій за замовчуванням:
$ restorecon -R -v /etc/NetworkManager/dispatcher.d/ -
Після виконання команди перезапустіть ноду через vSphere Client за шляхом Power > Restart Guest OS.
Якщо спостерігаються певні проблеми при перезапуску ноди, слід виконати наступний перезапуск за шляхом Power > Reset. -
Після перезапуску кожної ноди важливо переконатися, що вона успішно піднялася та отримала статус
Ready. Це можна зробити, виконавши командуoc get nodes. Після підтвердження, що нода працює належним чином і має статусReady, можна повторити процедуру для наступної ноди, яка все ще перебуває у статусіNot Ready. Цей підхід гарантує, що усі ноди кластера будуть стабільно працювати після оновлення.Важливо виконати цей процес для кожної ноди, яка зазнала проблем під час оновлення і має статус Not Ready, який не змінюється протягом часу. Це забезпечить, що всі ноди вашого кластера будуть оновлені та працюватимуть коректно. -
В якості додаткового кроку вирішення проблеми з нодами в
Not Readyстатусі в разі, якщо попердні кроки не спрацювали, можна виконати тимчасове переведенняSELinuxвPermissiveрежим. Для цього необхідно виконати наступну команду на кожній ноді в статусіNot Ready, підключившись до неї через SSH. Додаткове перезавантаження ноди не потрібне:$ setenforce 0 $ systemctl restart NetworkManagerПереведення SELinux в Permissive режим можливо лише тимчасово в ході процесу оновлення. Очікується, що режим SELinux автоматично зміниться на Enforcing в ході наступних кроків оновлення OKD версії, а саме п.14. -
Дочекайтеся оновлення OKD до версії
4.12.0-0.okd-2023-03-18-084815. -
Якщо ви плануєте зробити перерву і не продовжувати оновлення на OKD версію
4.12.0-0.okd-2023-04-16-041331одномоментно, рекомендується повернути режим на Enforcing самостійно. Для цього дочекайтесь успішного оновлення до версії4.12.0-0.okd-2023-03-18-084815та виконайте наступні команди в терміналі ноди:$ setenforce 1 $ systemctl restart NetworkManager
-
-
На інфраструктурі AWS, перед оновленням OKD до версії
4.12.0-0.okd-2023-04-16-041331, додайте перелік IP-адрес із сервісуrouter-defaultдо ресурсу ingresscontroller.-
Знайдіть ресурс з типом Service та імʼям router-default у просторі імен openshift-ingress та скопіюйте перелік IP адрес з анотації "service.beta.kubernetes.io/load-balancer-source-ranges"
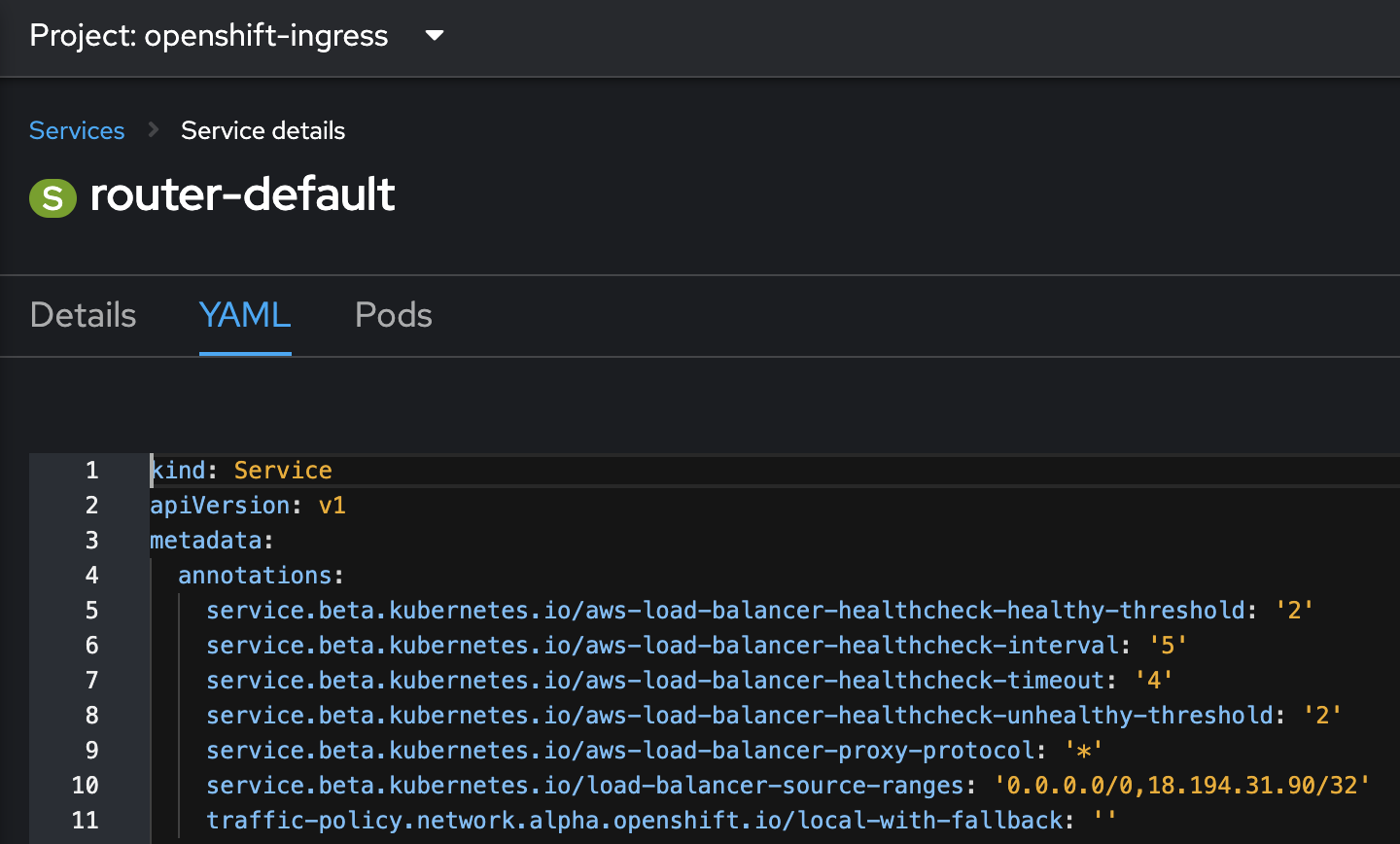 Зображення 4. router-default.yaml
Зображення 4. router-default.yaml -
Застосуйте цей перелік IP для ресурсу ingresscontroller з ім’ям
defaultу просторі іменopenshift-ingress-operator.$ oc patch ingresscontroller default -n openshift-ingress-operator --type='json' -p='[{"op": "add", "path": "/spec/endpointPublishingStrategy", "value": {"loadBalancer": {"allowedSourceRanges": ['${ip_list}'], "dnsManagementPolicy": "Managed", "scope": "External"}, "type": "LoadBalancerService"}}]'Змінну ${ip_list}замініть на скопійований раніше список IP-адрес. -
Якщо ви зіткнулися з помилкою
Command too longпри спробі внести зміни за допомогою командиoc patch, необхідно внести список IP-адрес до ресурсуingresscontrollerвручну. Для цього потрібно відредагувати YAML файл конфігураціїingresscontrollerз ім’ямdefault, розташований у просторі іменopenshift-ingress-operator. Внесіть необхідні зміни вручну, дотримуючись відповідної структури YAML.IP-адреси. YAML файл конфігурації
ingresscontrollerspec: endpointPublishingStrategy: loadBalancer: allowedSourceRanges: - 174.128.55.224/29 - 174.128.60.0/24 - 91.120.48.0/27 - 91.120.48.32/27 - 195.56.119.208/28 - 195.56.109.192/28 - 85.223.209.0/24 - 85.223.141.72/29 - 87.245.220.0/26 - 3.67.249.129/32 - 18.198.70.194/32 - 18.192.234.58/32 - 213.108.75.174/32 - 176.102.33.181/32 - 213.160.142.156/32 - 80.94.82.14/32 - 188.190.252.22/32 - 176.37.203.227/32 - 178.150.71.4/32 - 178.150.19.142/32 - 176.36.85.141/32 - 93.74.201.250/32 - 91.218.97.99/32 - 78.47.172.92/32 - 95.67.49.154/32 - 18.184.216.234/32 - 85.223.141.72/29 - 85.223.209.0/24 - 217.20.186.32/30 - 89.162.139.0/27 - 80.92.226.192/29 - 188.163.232.128/25 - 87.245.220.0/26 - 85.223.208.64/29 - 193.110.100.132/30 - 80.92.226.132/30 - 85.223.157.168/29 - 91.202.109.220/30 - 46.164.141.64/29 - 94.153.227.200/30 - 94.153.227.200/30 - 217.20.173.100/30 - 83.170.216.64/27 - 176.102.36.64/26 - 3.122.30.161/32 - 3.123.171.165/32 - 3.125.134.79/32 - 3.65.5.240/32 - 3.73.147.132/32 dnsManagementPolicy: Managed scope: External type: LoadBalancerService
-
-
На інфраструктурі vSphere, перед оновленням OKD до версії
4.12.0-0.okd-2023-04-16-041331, замініть образfedora-coreosдля шаблону VM. Це пов’язано з виявленим багом, який може ускладнити створення нових нод після оновлення до версії OKD4.12.0-0.okd-2023-03-18-084815. Докладніше про цей баг та інструкції щодо його вирішення можна знайти за посиланням Red Hat Solution 6979105.Для розв’язання цієї проблеми, виконайте наступні кроки.
-
Завантажте образ RHCOS OVA версії
37.20230218.3.0. Це можна зробити на сайті https://builds.coreos.fedoraproject.org/browser?stream=stable&arch=x86_64 або за посиланням. -
Відкрийте vSphere Client та перейдіть до директорії кластера, де планується оновлення шаблону VM. Натисніть правою клавішею миші по назві директорії та оберіть пункт Deploy OVF Template.
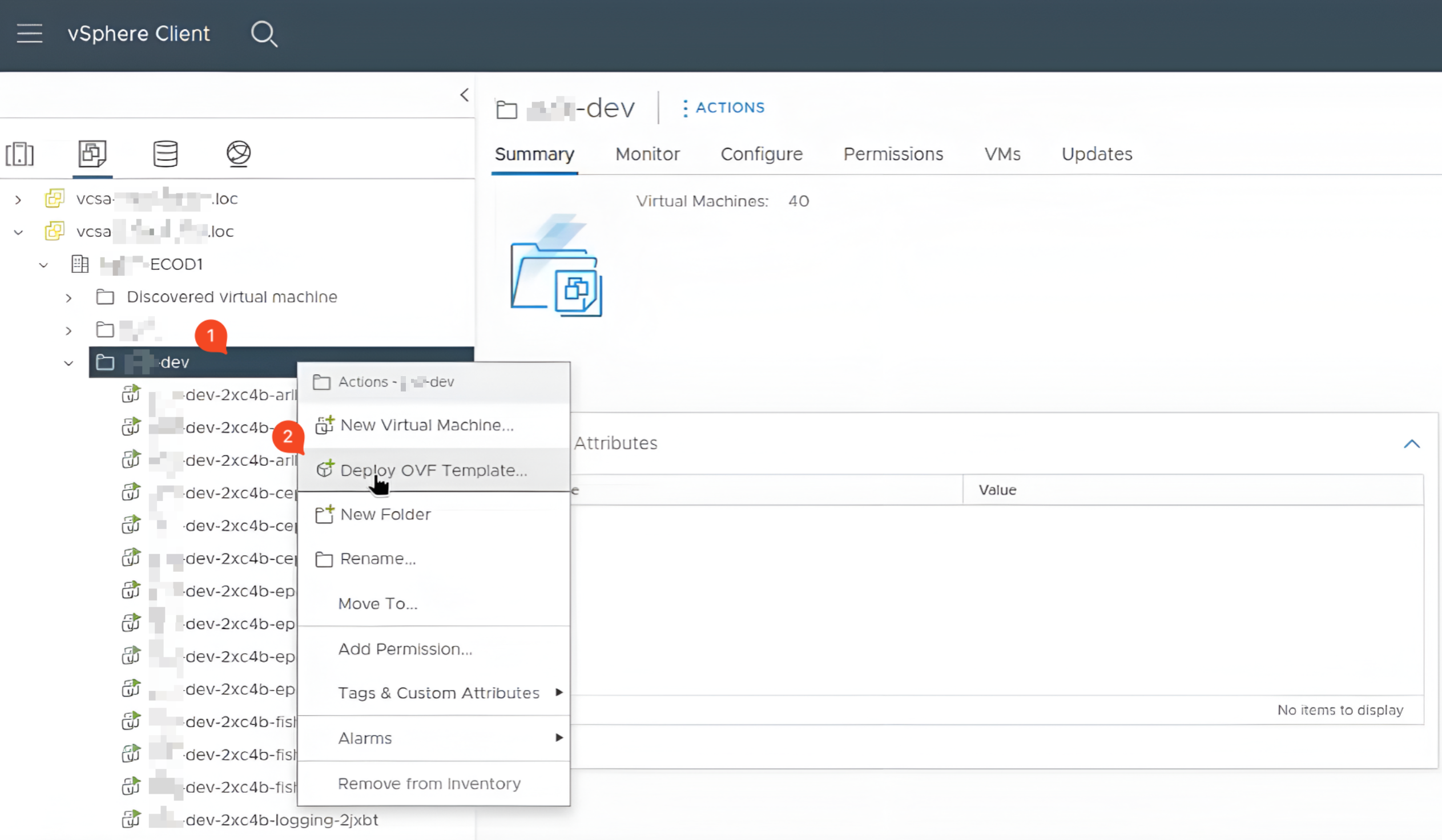
-
Автоматично відкриється вікно Deploy OVF Template.
-
У першому розділі Select an OVF template оберіть пункт Local file та вкажіть шлях до образу RHCOS OVA, який було завантажено у пункті Завантаження образу RHCOS OVA.
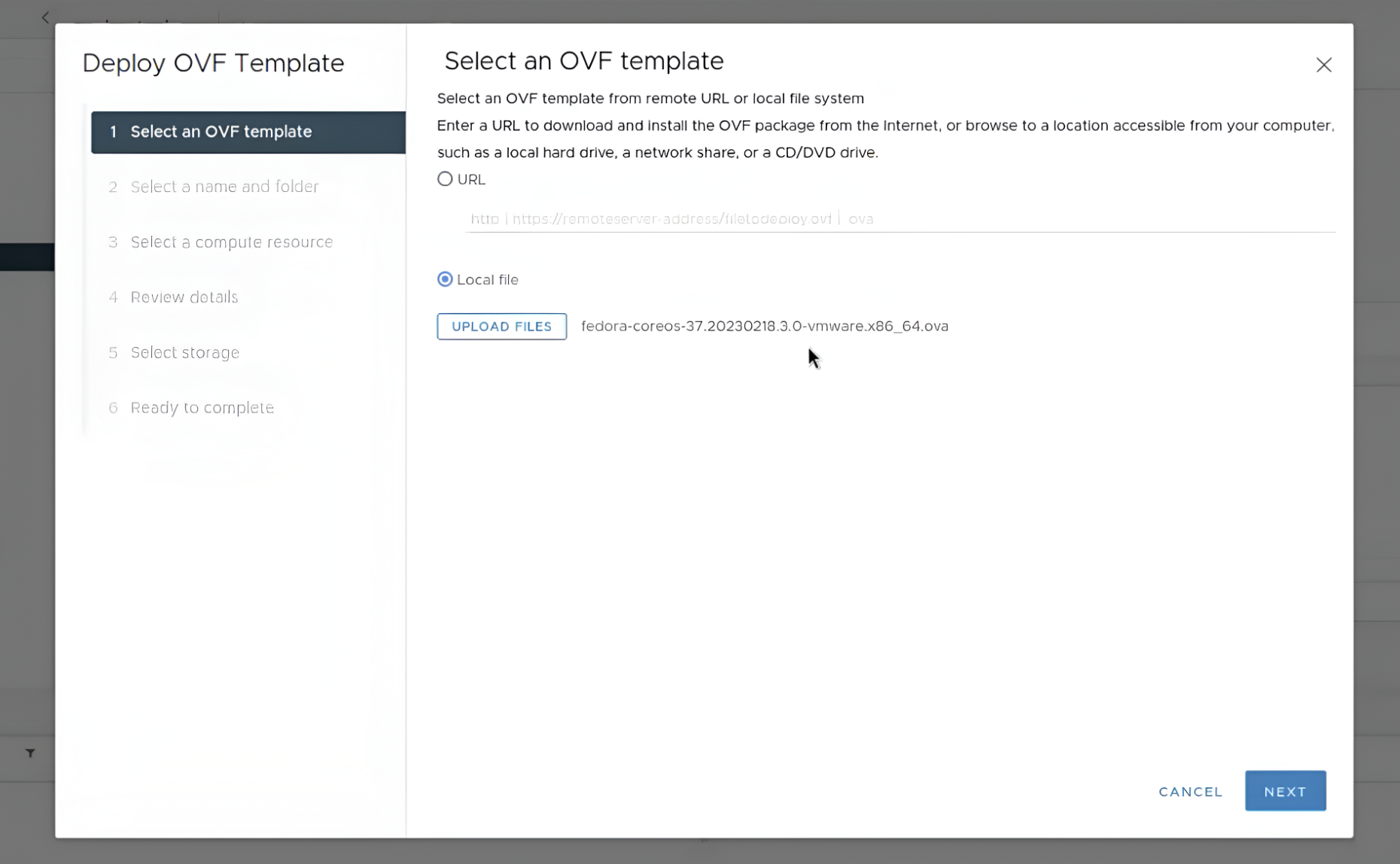
-
У другому розділі Select a name and folder введіть будь-яку назву для віртуальної машини та оберіть директорію вашого кластера.
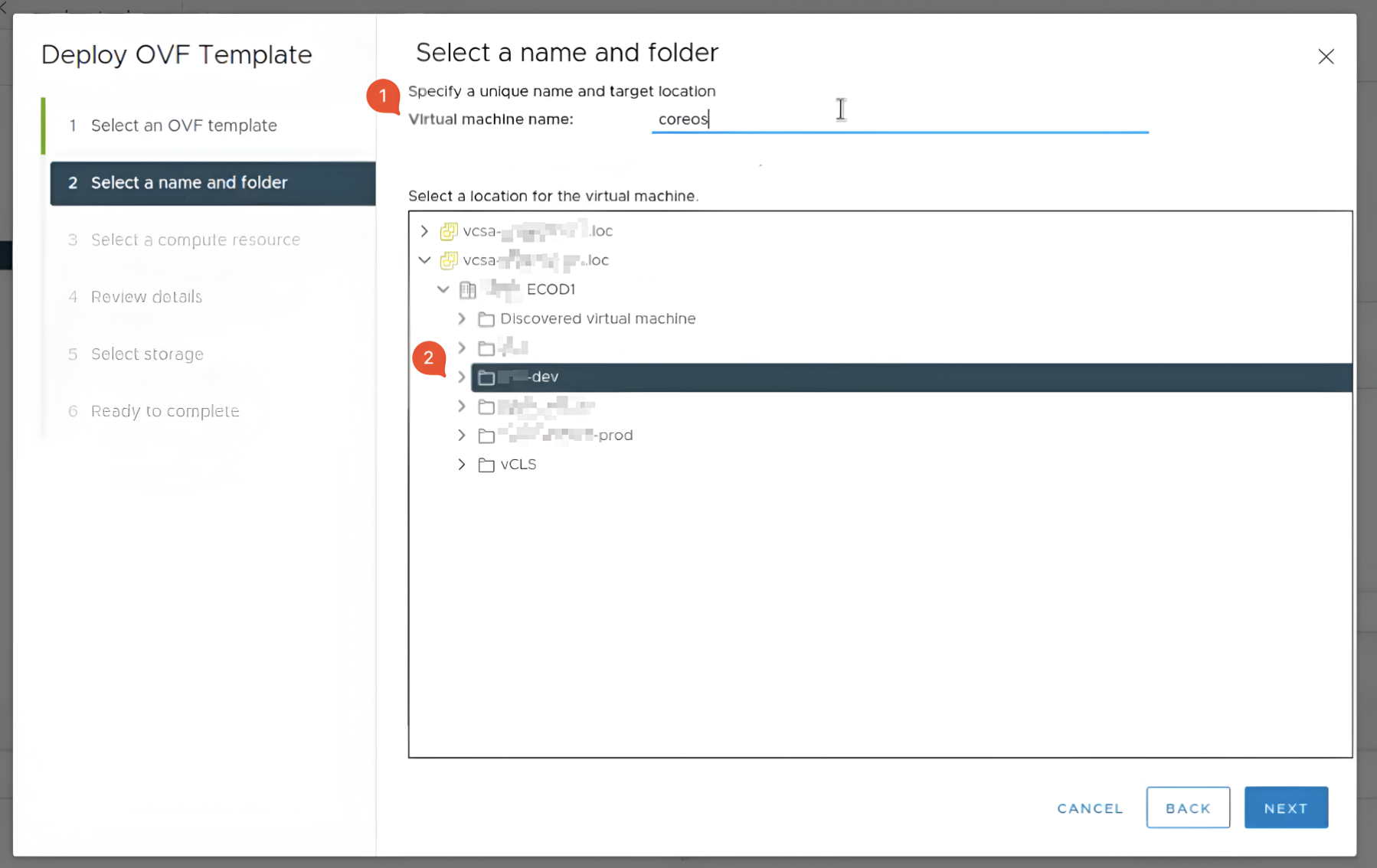
-
У третьому розділі Select a computer resource оберіть обчислювальний ресурс в якому буде знаходитись віртуальна машина.
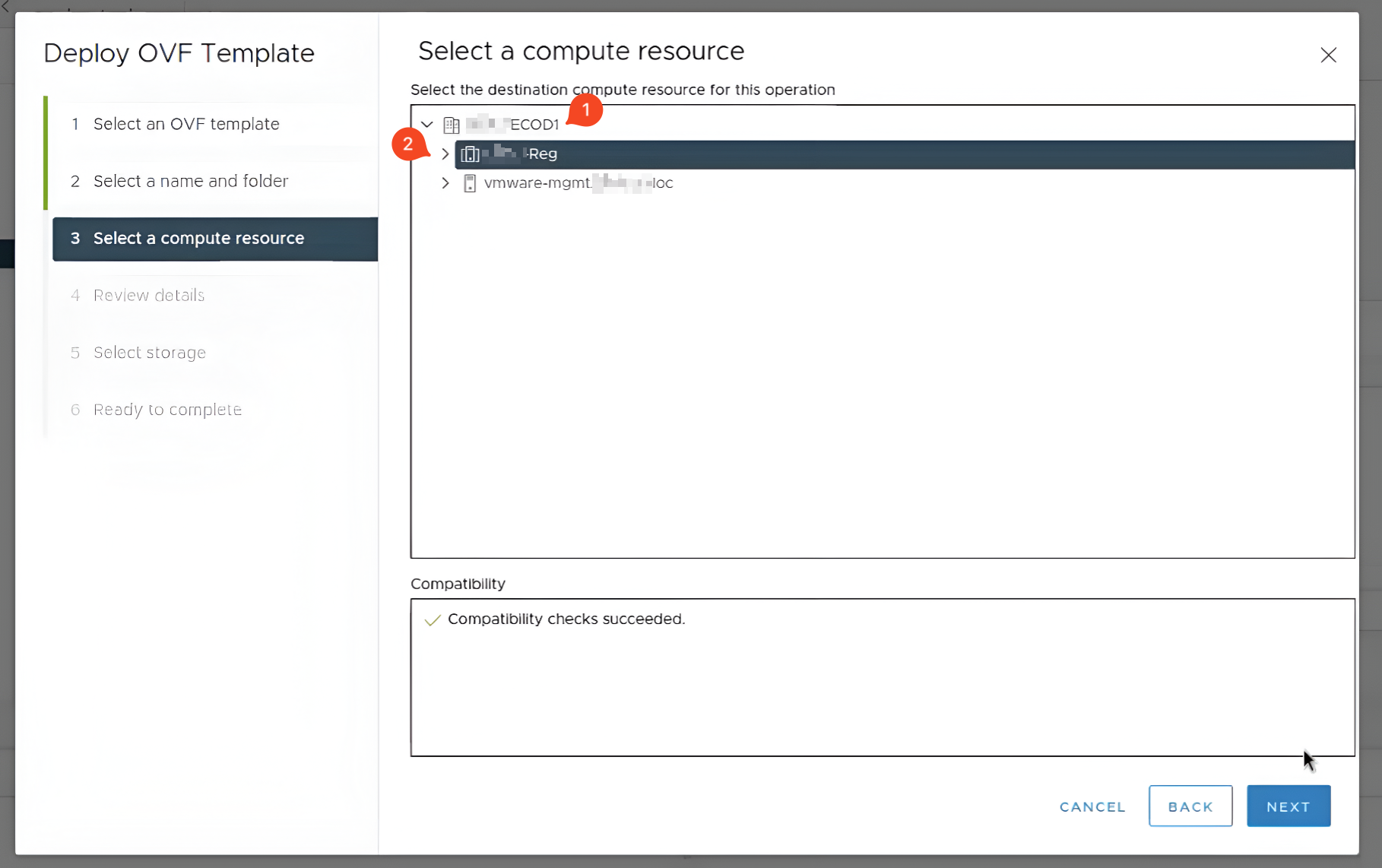
-
У п’ятому розділі Select storage оберіть сховище, в яке бажаєте зберегти віртуальну машину.
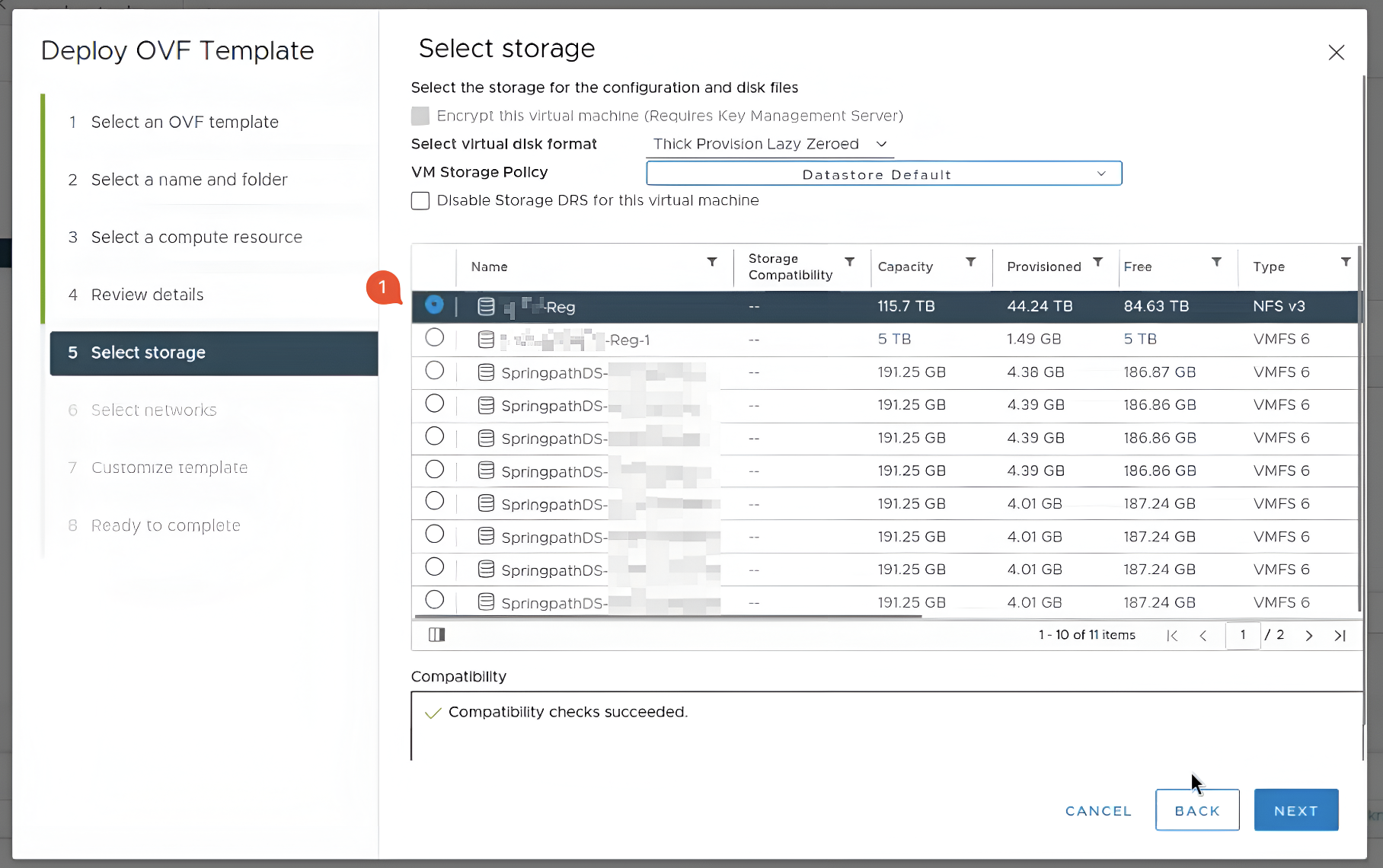
-
У шостому розділі Select networks оберіть мережу для віртуальної машини.
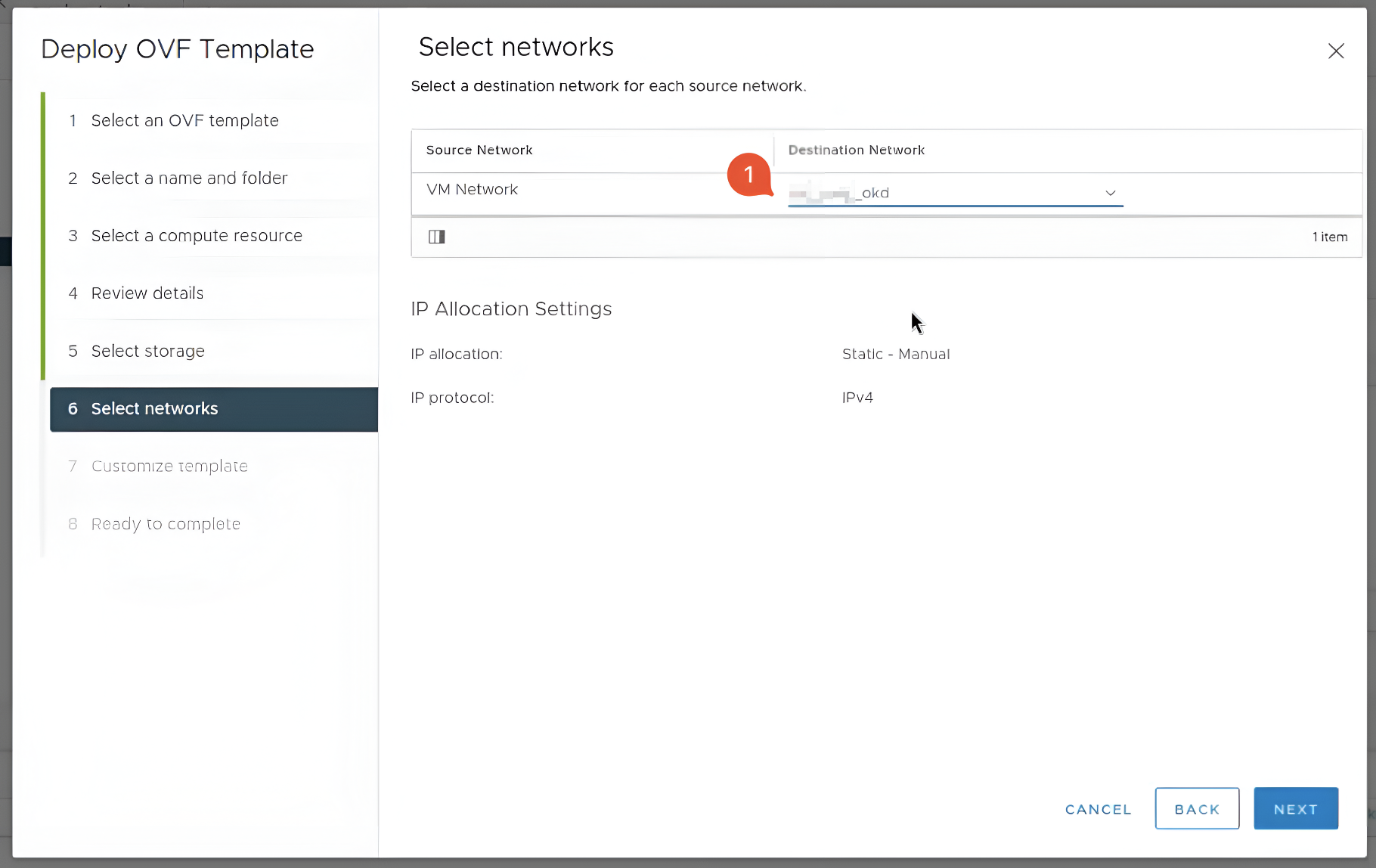
-
Сьомий розділ Customize template залиште без змін.
-
У восьмому розділі натисніть кнопку
Finish.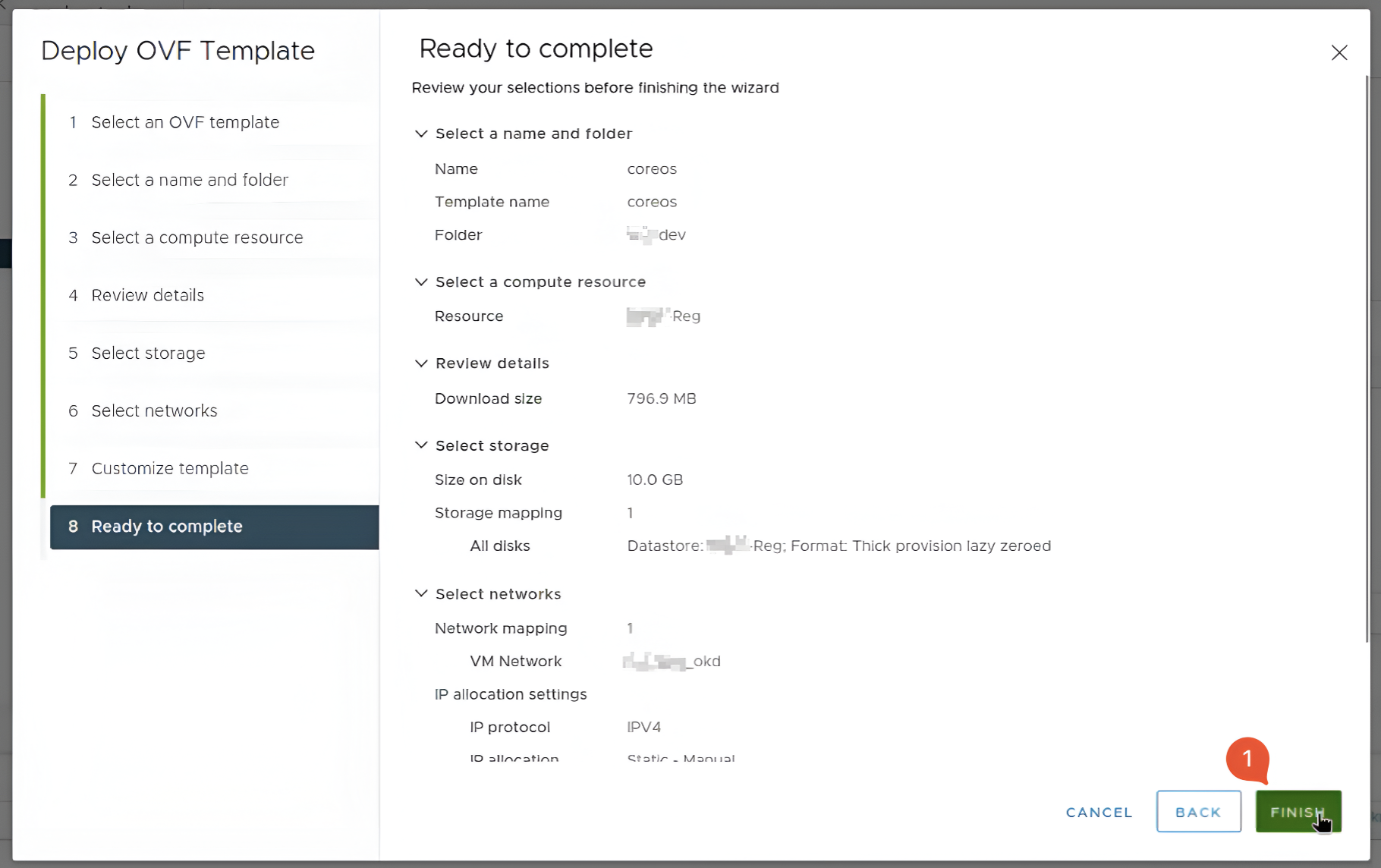
-
-
Зачекайте, поки буде створена нова віртуальна машина у нижній частині vSphere Client.

-
Для подальшого створення VM-шаблону знайдіть старий шаблон, з якого запускалися ноди, та скопіюйте його назву.
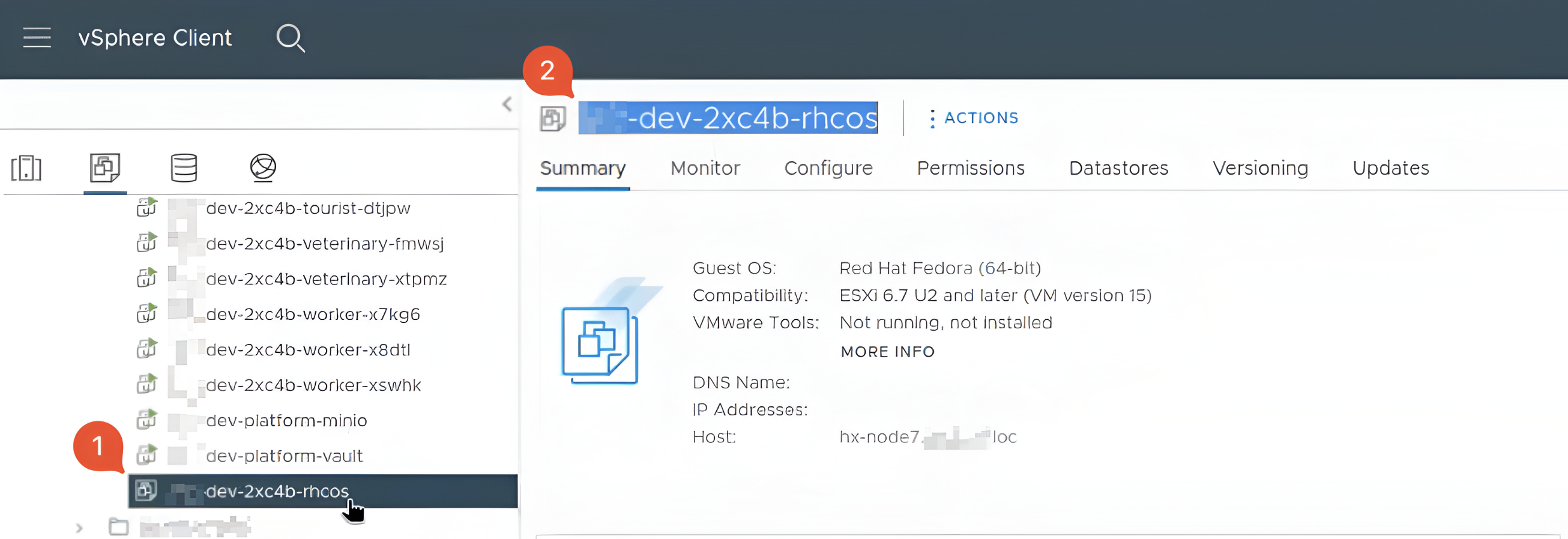
-
Знайдіть новостворену віртуальну машину (крок Розгортання OVF-шаблону) у директорії кластера. Натисніть по назві правою клавішею миші та оберіть пункт
Clone>Clone to Template.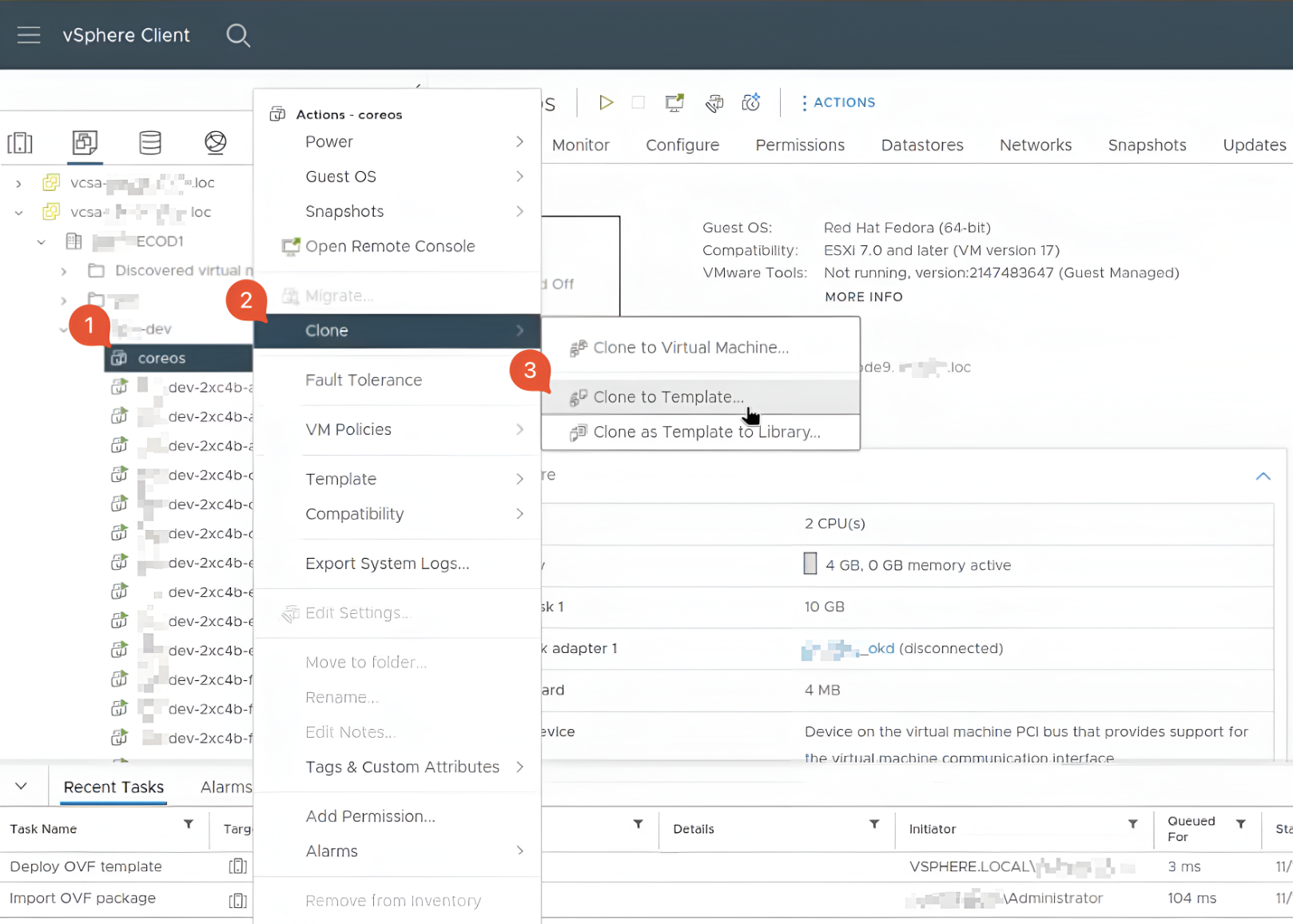
-
Автоматично відкриється вікно Clone Virtual Machine to Template.
-
У першому розділі Select a name and folder введіть назву шаблону, яка була скопійована на кроці Копіювання назви шаблону VM, та допишіть до назви суфікс
-1(бо старий шаблон зі старою назвою досі існує). Також оберіть директорію кластера.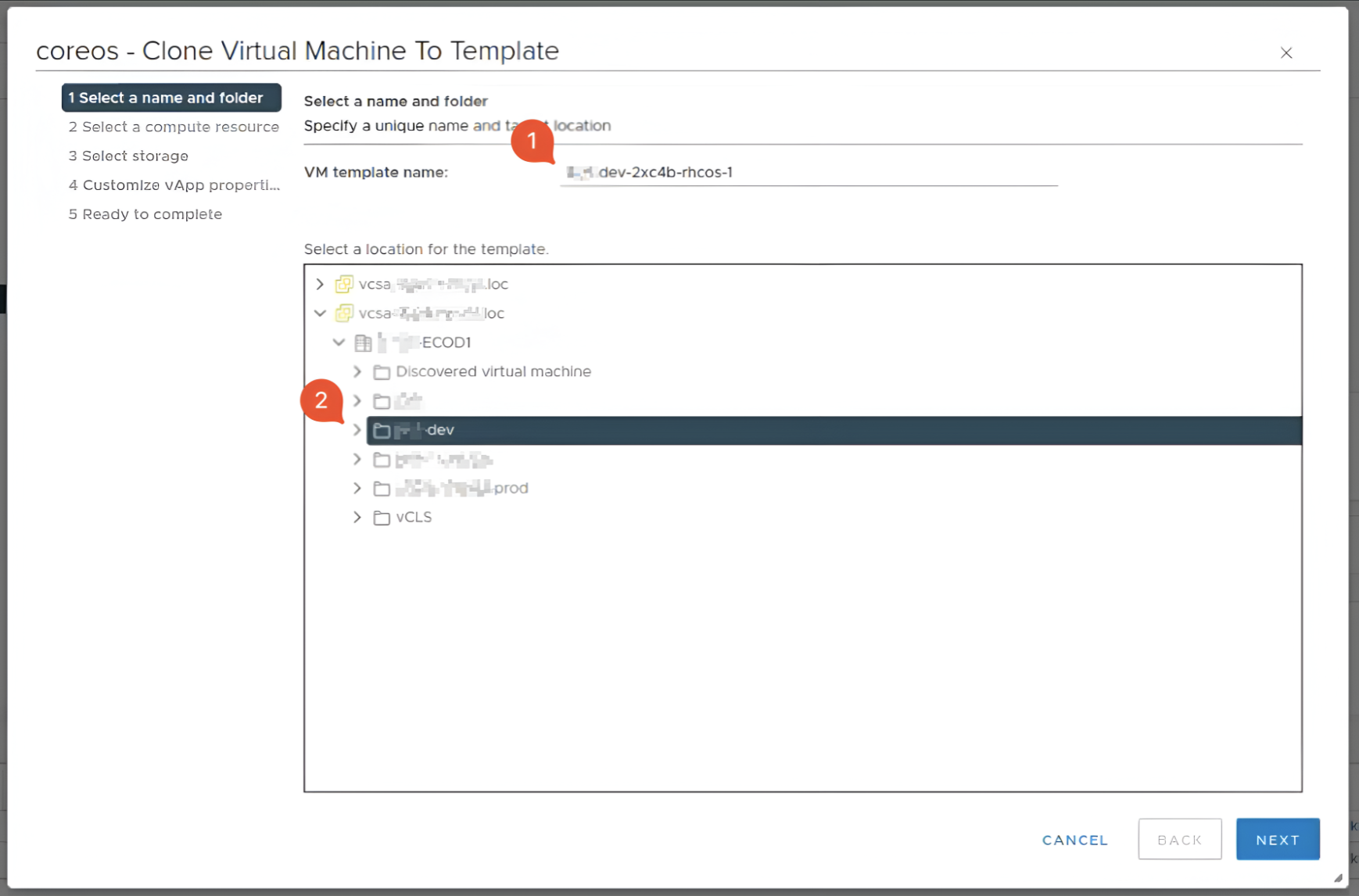
-
У другому розділі Select a compute resource оберіть обчислювальний ресурс, в якому буде знаходитися шаблон.
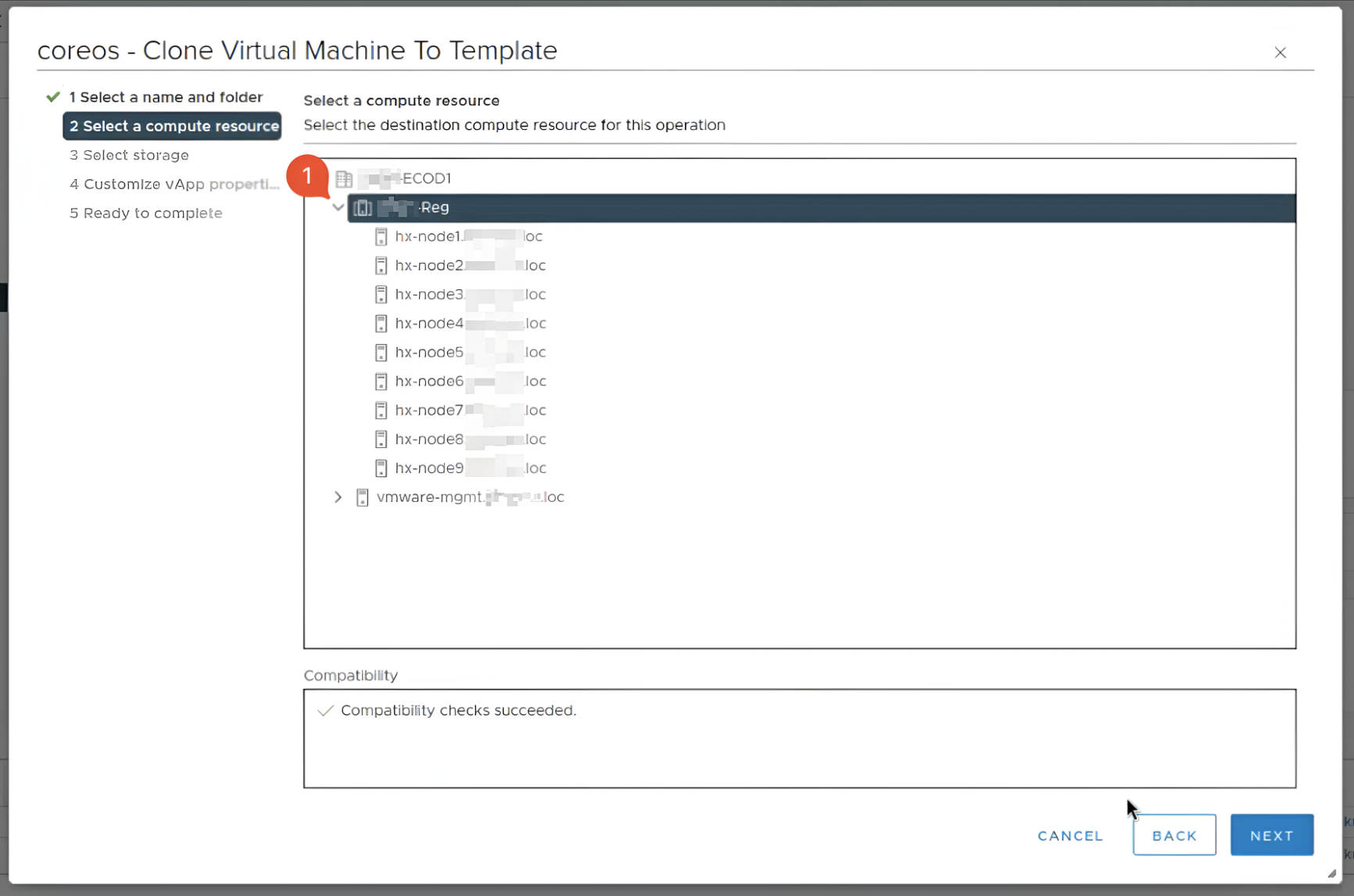
-
У третьому розділі Select storage оберіть сховище, до якого бажаєте зберегти шаблон.
-
Четвертий розділ Customize vApp залиште без змін.
-
У п’ятому розділі Ready to complete натисніть кнопку
Finish.
-
-
Переконайтеся, що директорія кластера містить два шаблони:
-
Старий
-
Новий із суфіксом
-1. Новий шаблон повинен мати оновлені дані на вкладці Summary.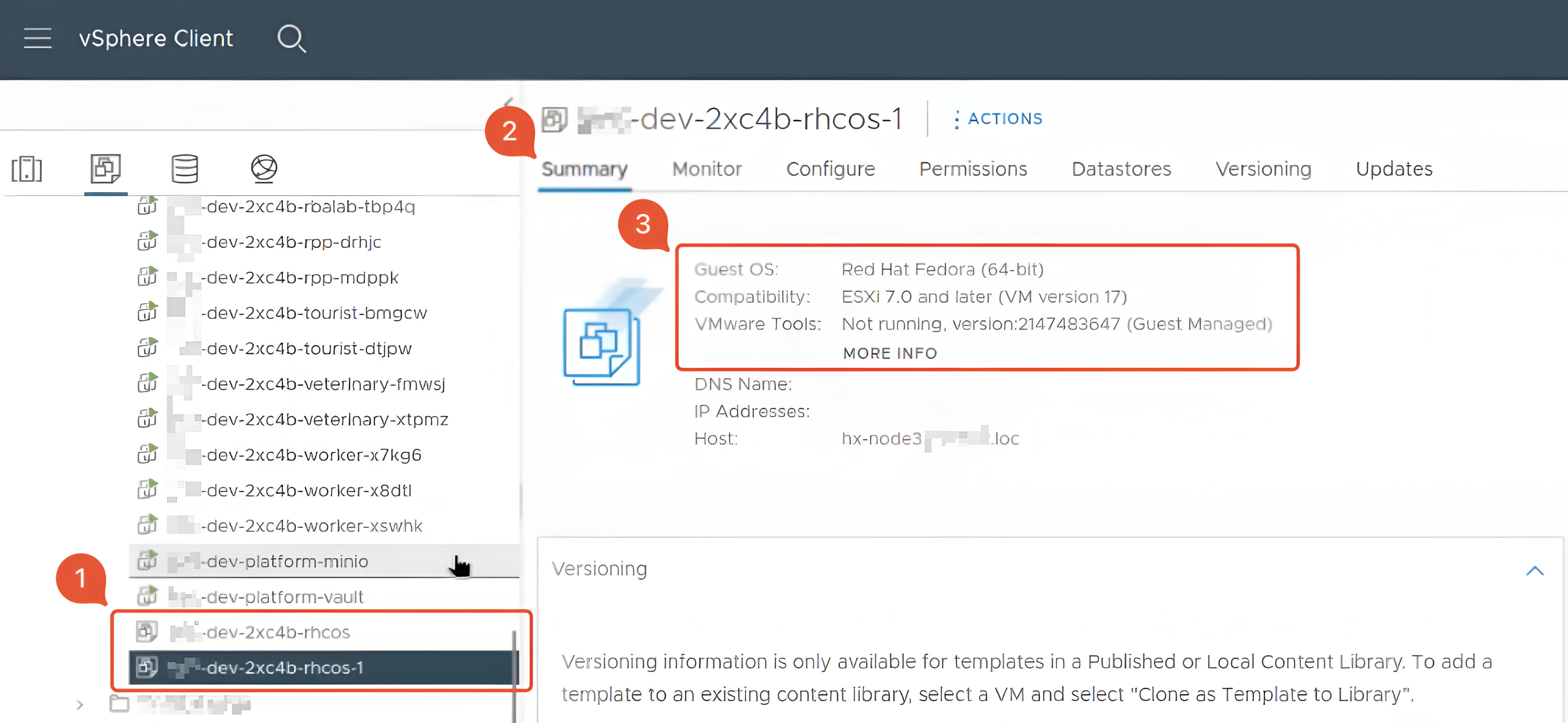
-
-
Новий шаблон успішно створений та готовий до використання. Але щоб новий шаблон міг використовувати OKD, надайте йому назву, як у попереднього шаблону, тобто видаліть суфікс
-1. Це можна зробити двома способами: або видалити старий шаблон, або перейменувати його. Для цього у директорії кластера знайдіть старий шаблон, натисніть на нього правою клавішею миші та оберіть один із двох варіантів:RenameабоDelete form Disk. У випадку перейменування, до назви слід додати будь-яку послідовність цифр чи літер.
-
Останньою дією є перейменування новоствореного шаблону, а саме прибирання суфікса
-1. Для цього у директорії кластера знайдіть новий шаблон з приставкою -1, натисніть на нього правою клавішею миші та оберіть пунктRename.
Автоматично відкриється вікно перейменування. Далі приберіть приставку -1.
-
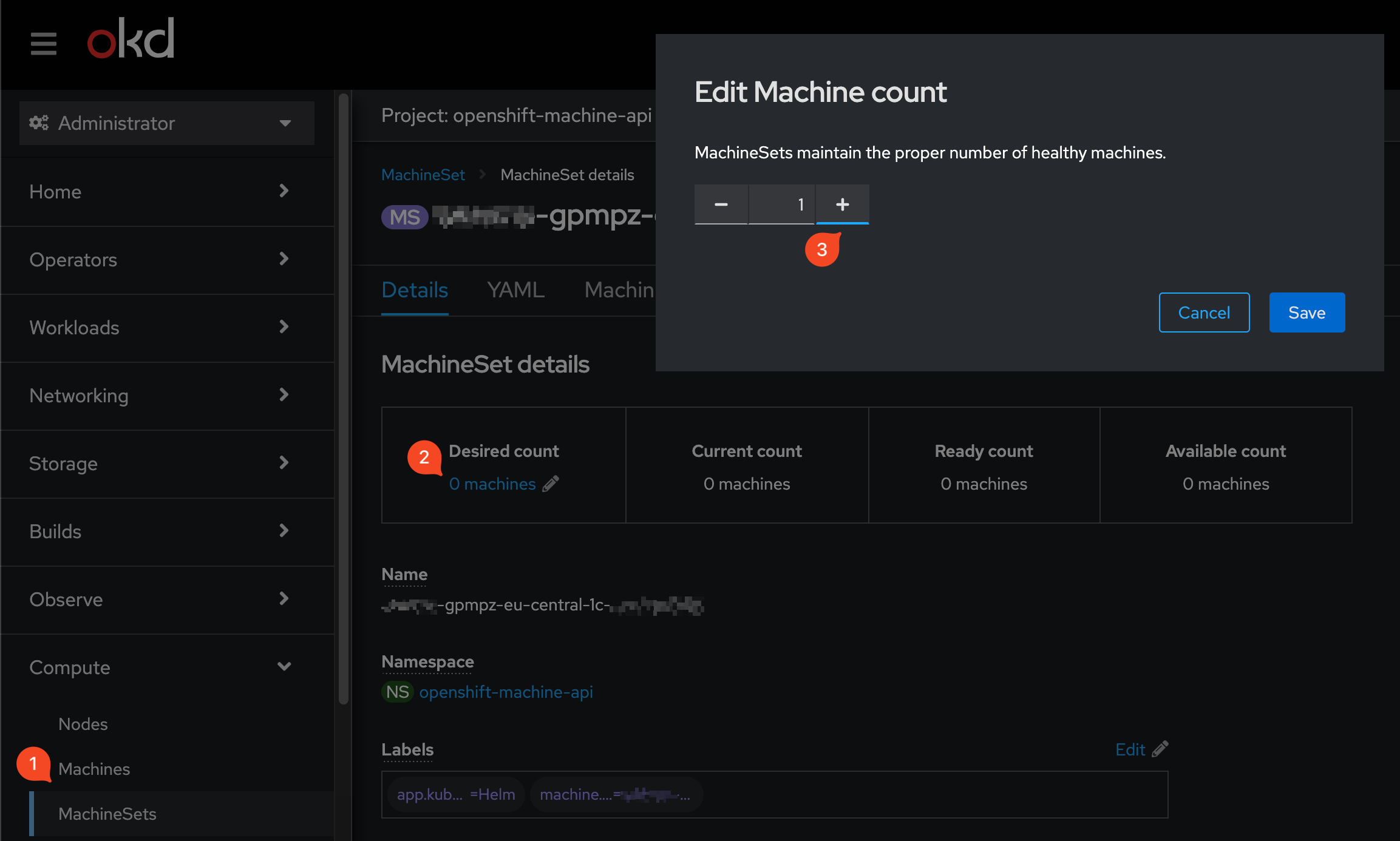
(Опційно) Для перевірки працездатності можна спробувати підняти один інстанс для будь-якого реєстру в OKD. Для цього в OKD оберіть розділ machineSets, знадіть потрібний машин-сет реєстру та встановіть кількість реплік у значення
1.
-
-
Після успішного додавання переліку IP до ресурсу ingresscontroller (для AWS-інфраструктури) або заміни образу
fedora-coreosдля VM-шаблону (для vSphere-інфраструктури), у розділі Administration > Cluster Settings натисніть кнопкуSelect a versionта оберіть версію OKD4.12.0-0.okd-2023-04-16-041331.При оновленні OKD до версії 4.12.0-0.okd-2023-04-16-041331може з’явитися помилка"message: Retrieving payload failed version="4.12.0-0.okd-2023-04-16-041331""(див. детальніше — https://github.com/okd-project/okd/discussions/1566#discussioncomment-5633599).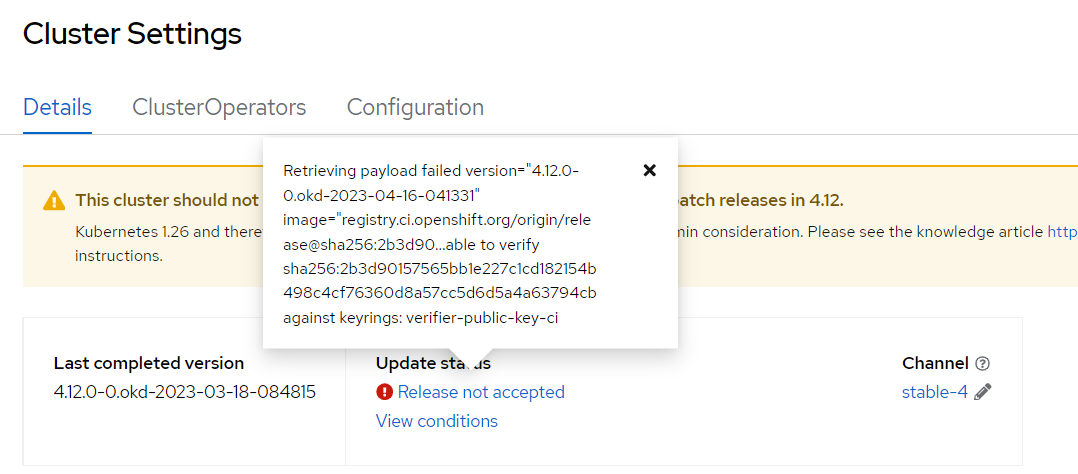 Зображення 5. Приклад помилки
Зображення 5. Приклад помилкиДля розв’язання цієї проблеми, виконайте наступну команду через термінал.
$ oc patch --type='merge' --patch='{"spec":{"desiredUpdate":{"force":true}}}' clusterversion version -
Після успішного оновлення OKD до версії
4.12.0-0.okd-2023-04-16-041331, зніміть ресурс MachineHealthCheck з паузи.$ oc get machinehealthcheck -n openshift-machine-api $ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused- -
Увімкніть розгортання (deployment) istiod.
$ oc scale deployment istiod --replicas=2 -n istio-system -
У ресурсі istioOperator з ім’ям istiocontrolplane, у просторі імен
istio-systemsвстановіть поле enabled у значенняtrueдля блоку з імʼямistio-ingressgateway-control-plane-main.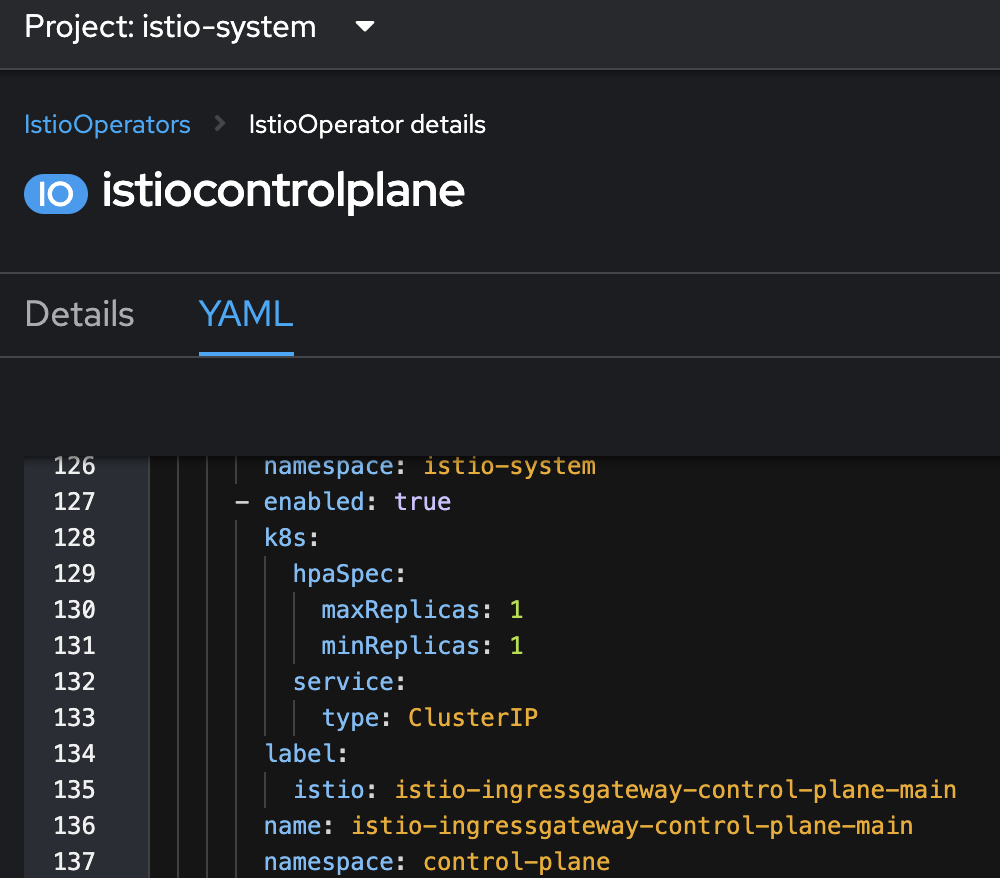
-
Увімкніть вимкнені реєстри.
Рекомендовано запускати по 1-2 реєстри за раз запропонованим bash-скриптом, що виконує наступні дії для кожного реєстру (кодової бази):
-
Виконує патч ресурсу istiocontrolplane для повернення роботи
istioдля реєстру. -
Переводить усі CronJob реєстру в активний стан.
-
Масштабує кількість реплік для MachineSet реєстру відповідно до анотації (якщо анотації не знайдено, значення кількості реплік за замовчуванням дорівнює 2).
Приклад синтаксису запуску скрипту файлом
./registry_turn_on.sh <registry-name>, де<registry-name>— назва реєстру, вводити без< >. Наприклад:./registry_turn_on.sh test-registry.registry_turn_on.sh
#!/usr/bin/env bash PATCH-ISTIO() { echo "Turning on Istio ingress gateway in registry ${1}" indexOfIstioIngressGateways=$(oc get -n istio-system IstioOperator istiocontrolplane -o json | jq '.spec.components.ingressGateways | map(.namespace == "'${1}'") | index(true)') oc patch -n istio-system IstioOperator istiocontrolplane --type json -p '[{"op": "replace", "path": "/spec/components/ingressGateways/'${indexOfIstioIngressGateways}'/enabled", "value": true}]' } registry=${1} echo "Registry is ${registry}" registryMachineSet=$(oc get -n openshift-machine-api MachineSet -o=jsonpath='{.items[?(@.metadata.annotations.meta\.helm\.sh/release-namespace=="'"${registry}"'")].metadata.name}') registryMachineSetReplicas=$(oc get -n openshift-machine-api MachineSet ${registryMachineSet} -o jsonpath='{.spec.replicas}') if [ $registryMachineSetReplicas -eq 0 ]; then echo "Turn on registry ${registryMachineSet}" PATCH-ISTIO "${registry}" for cronjob in $(oc get -n velero CronJobs -o jsonpath='{range .items[*].metadata}{.name}{"\n"}{end}' | grep ${registry}); do echo "Unsuspend CronJob ${cronjob}" oc patch -n velero CronJobs ${cronjob} -p '{"spec":{"suspend":true}}' done isAnnotationPresent=$(oc get -n openshift-machine-api MachineSet ${registryMachineSet} -o=jsonpath='{.metadata.annotations.registryMachineSetReplicas}') if [ ${isAnnotationPresent} ]; then echo "Annotation [registryMachineSetReplicas] is present in MachineSet ${registryMachineSet}" echo "Scale up ${registryMachineSet} to ${isAnnotationPresent} replicas" oc scale -n openshift-machine-api --replicas=${isAnnotationPresent} MachineSet ${registryMachineSet} else echo "Annotation [registryMachineSetReplicas] is not present in MachineSet ${registryMachineSet}" echo "Scale up ${registryMachineSet} to 2 replicas by default" oc scale -n openshift-machine-api --replicas=2 MachineSet ${registryMachineSet} fi else echo "Registry ${registryMachineSet} is running" fi -
-
Поверніть кількість worker-нод з 4 до 3 реплік.
-
Оновіть вручну
ocs-оператор через вебінтерфейс OKD.Кроки для оновлення:
-
Для ресурсу Subscriptions із назвою ocs-operator у просторі імен
openshift-storageзмініть наступні поля:.spec.channel - "stable-4.12"
.spec.installPlanApproval - "Automatic"
.spec.startingCSV - "ocs-operator.v4.12.0"
-
Для ресурсу Subscriptions із назвою mcg-operator-stable-4.11-redhat-operators-openshift-marketplace у просторі імен
openshift-storageзмініть наступні поля:.spec.channel - "stable-4.12"
.spec.installPlanApproval - "Automatic"
При спробі редагування ресурсів Subscriptions можуть виникати помилки.
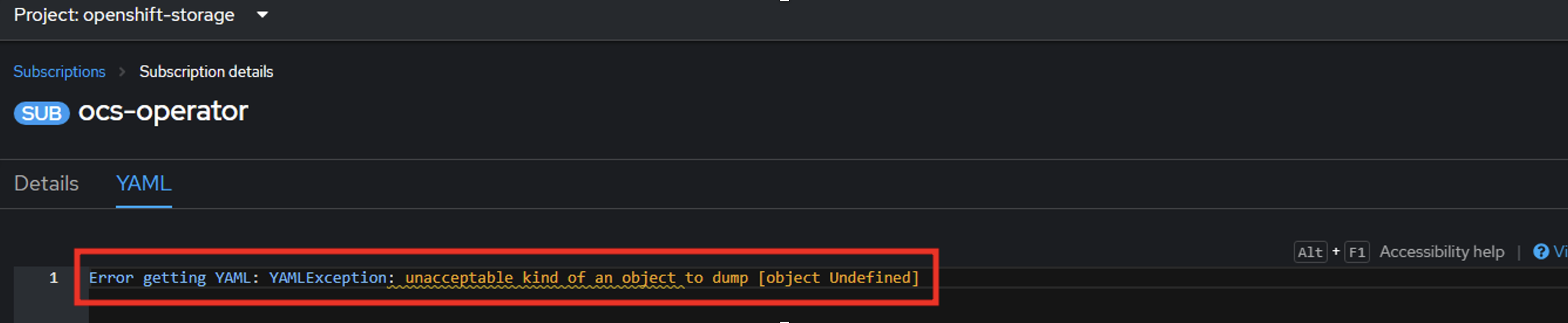
Для розв’язання цієї проблеми слід скористатися наступними командами та редагувати ресурси через термінал.
$ oc -n openshift-storage get subscriptions –o wide $ oc -n openshift-storage edit subscription ocs-operator $ oc -n openshift-storage edit subscriptions mcg-operator-stable-4.11-redhat-operators-openshift-marketplace(Опційно) Якщо після внесених змін автоматично не почалось оновлення ocs-operator, перейдіть до оператора OpenShift Container Storage та запустіть оновлення вручну.
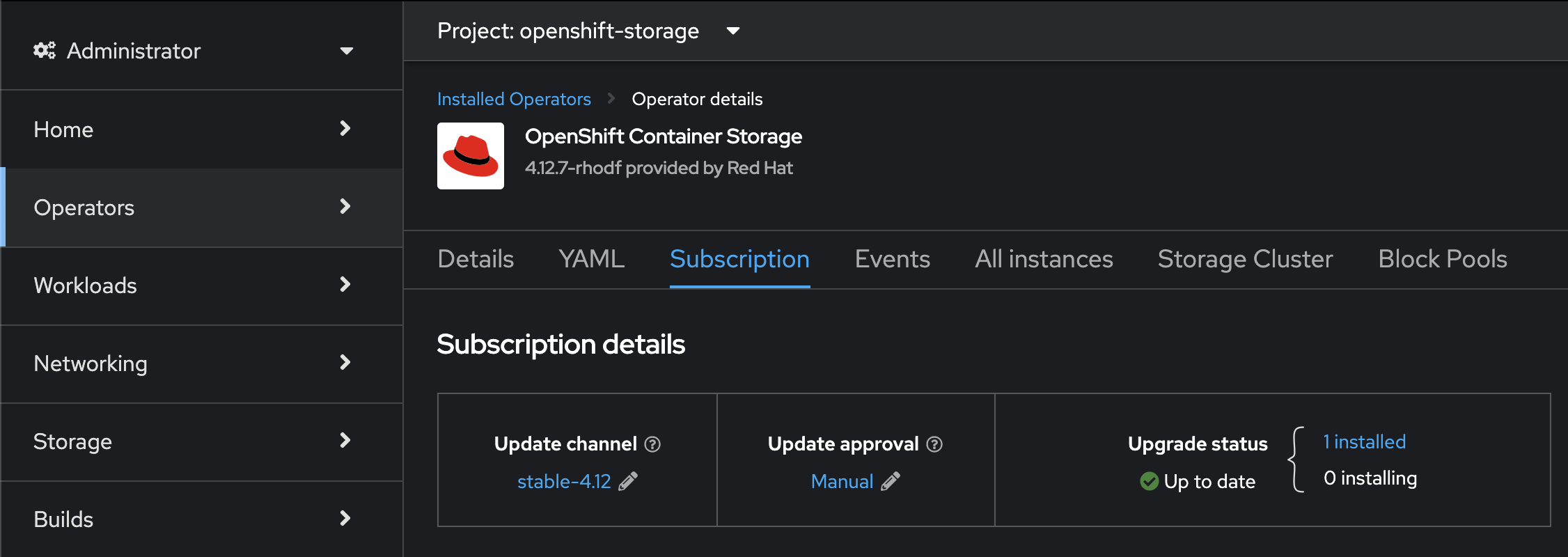
Через проблему відображання оператора OpenShift Container Storage на вкладці Operators > Installed Operators, знайти оператор можна через Deployment ocs-operator, у просторі імен openshift-storage. Після віднайдення Deployment, натисніть посилання у рядку Managed by, яке веде на сторінку оператора.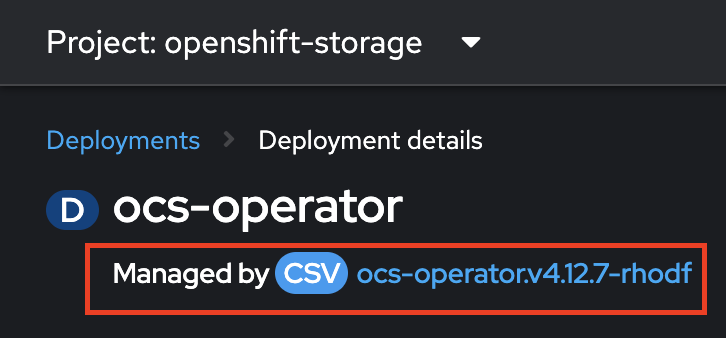
-
-
Запустіть cluster-mgmt пайплайн.
4. Ключові проблеми, що були вирішені під час процесу оновлення OKD
Проблеми, які не були зазначені в офіційній документації та рекомендаціях:
-
Проблема з ресурсом Machine Config Pool. MCP для мастер-нод не міг знайти потрібний ресурс Machine Config.
-
Проблема з невалідним значенням Upstream configuration, через яке не починалось оновлення кластера.
-
Проблема працездатності
redis-operatorна OKD 4.12 та подальше його оновлення до сумісної з OKD 4.12 версії. -
Проблема працездатності
kafka-operatorна OKD 4.12 та подальше його оновлення до сумісної з OKD 4.12 версії. -
Проблема оновлення та працездатності
ocs-operatorна OKD 4.12 через невалідні CRDs. -
Проблема видалення компонента NooBaa через ресурс StorageCluster.
-
Проблема працездатності
istio-operatorна OKD 4.12 та Ceph, та подальше його оновлення до сумісної з OKD 4.12 версії. -
Проблема працездатності поди
mailu-postfixчерез помилку"fatal: the Postfix mail system is already running"після оновлення до OKD 4.12. -
Проблема невалідного оновлення OKD 4.11 на 4.12 через несумісний базовий образ (base image) мастер-нод, та подальша ручна заміна AMI для розв’язання проблеми.
-
Проблема оновлення OKD на плагінах OVNKubernetes та OpenshiftSDN.
-
Непрацездатність
master- таworker-нод при оновленні OKD до 4.12 через системні сервісиovsdb-server,openvswitch,systemd-sysusersтаunbound-anchor. -
Проблема зупинки оновлення
worker-нод через ресурс PodDisruptionBudgets, який блокував процесdrain. -
Проблема з доступом до
master- таworker-нод та подальше блокування процесу траблшутингу через відсутність доступу за SSH-ключем та авторизації за паролем. -
Проблема з
kubelet-процесом на мастер-нодах при оновленні OKD до 4.12 на мережевому плагіні OVNKubernetes. -
Проблема працездатності поду
machine-config-operatorтаmachine-config-controller, через що процес оновлення OKD зупинявся. -
Проблема з SELinux при оновленні на vSphere (у процесі підтвердження).
-
Проблема зміни хеш-суми образів для OKD 4.12, через що процес оновлення OKD не починався.
-
Проблема працездатності реєстрів на нових агентах із новою версією
oc cli. -
Проблема оновлення
ocs-operatorна OKD 4.12. Не починалося оновлення після оновлення версії в ресурсі Subscription.
5. Потребує подальшого тестування
-
Оновлення OKD на vSphere — у процесі.
-
QA-тестування сценаріїв Install/Update (OKD, Платформи, реєстрів) на AWS — у процесі.
-
QA-тестування сценаріїв Install/Update (OKD, Платформи, реєстрів) на vSphere.
-
QA-тестування резервного копіювання та відновлення компонентів Control Plane та реєстрів — у процесі.
-
Оновлення OKD з версії
4.11.0-0.okd-2022-07-29-154152, що розгорнута у середовищі EnvOne, КРРТ. -
Резервне копіювання та відновлення
master-ів та etcd. -
Загальний Recovery-процес у випадку зупинки або невдалого оновлення OKD.