Дебаг під час моделювання регламенту реєстру
Дебаг — це процес виявлення, аналізу та виправлення помилок або дефектів, що можуть статися під час розробки регламенту. Під час дебагу розробник здійснює систематичний аналіз коду за допомогою різних інструментів, щоб знайти причину помилок.
1. Загальний опис
Під час розробки регламенту розробник може зіштовхнутися з виникненням помилок на різних етапах, тому важливо вміти відстежувати джерела та причини виникнення помилок, виконувати відлагодження їх та виправляти.
| Детальніше про типові помилки, з якими зіштовхується розробник, і методами їх виправлення можна ознайомитися на сторінці Типові помилки та алгоритм їх усунення. |
Залежно від етапу розробки, застосовуються різні техніки дебагу в різних застосунках:
-
Відстеження помилок при розробці data-model.
-
Відстеження помилок під час збірки регламенту у застосунку Jenkins.
-
Дебаг groovy-скриптів з виводом у консоль або в середовищі розробки — IntelliJ IDEA.
-
Відстеження помилок при розробці бізнес-процесу у застосунку Camunda.
-
Додаткові можливості дебагу.
2. Відстеження помилок при розробці data-model
| Розробник має керуватися загальними вимогами щодо створення моделі даних. |
| При створенні changeSet розробник має брати до уваги наявні обмеження на використання ідентифікаторів чи імен таблиць та полів. Детальніше про ключові слова див. за посиланням: https://www.postgresql.org/docs/current/sql-keywords-appendix.html |
2.1. IntelliJ IDEA
Для створення фізичної моделі даних під час розробки регламенту реєстру використовується Liquibase — система управління версіями баз даних, що описується за допомогою строго типізованих XML-шаблонів.
IntelliJ IDEA є потужним середовищем розробки з широкими функціональними можливостями для написання та дебагу коду. Якщо у вашому коді не вистачає закриваючого тегу, IntelliJ IDEA автоматично підкреслить місця помилок:
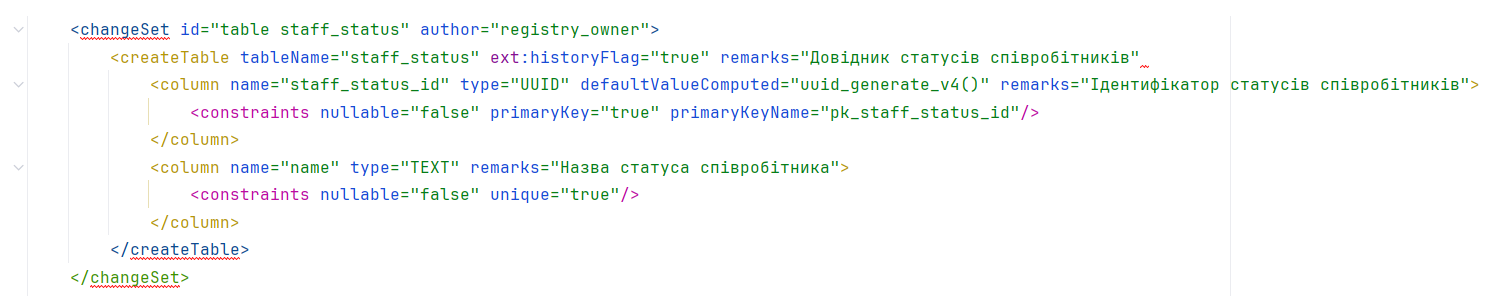
Для уникнення помилок під час створення changeSet рекомендується використовувати актуальні теги та атрибути згідно з документацією:
Основна перевірка на правильність створення changeSet відбувається на етапі виконання пайплайну MASTER-Code-review-registry-regulations. Після внесення змін до моделі даних рекомендується дочекатися автоматичної перевірки коду.
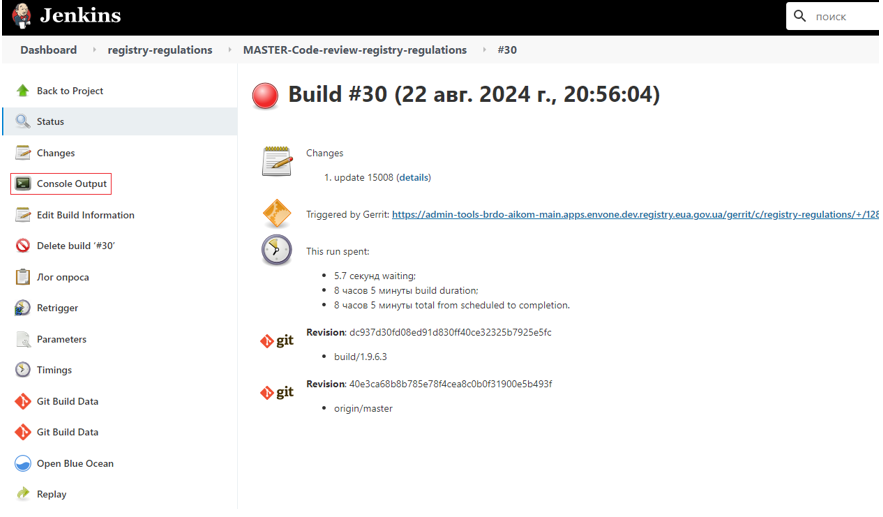
На малюнку під цифрою 1 вказано статус процесу виконання (білд розпочато), на якому зараз знаходиться зміна. Під цифрою 2 вказана назва pipeline, який зараз виконується.
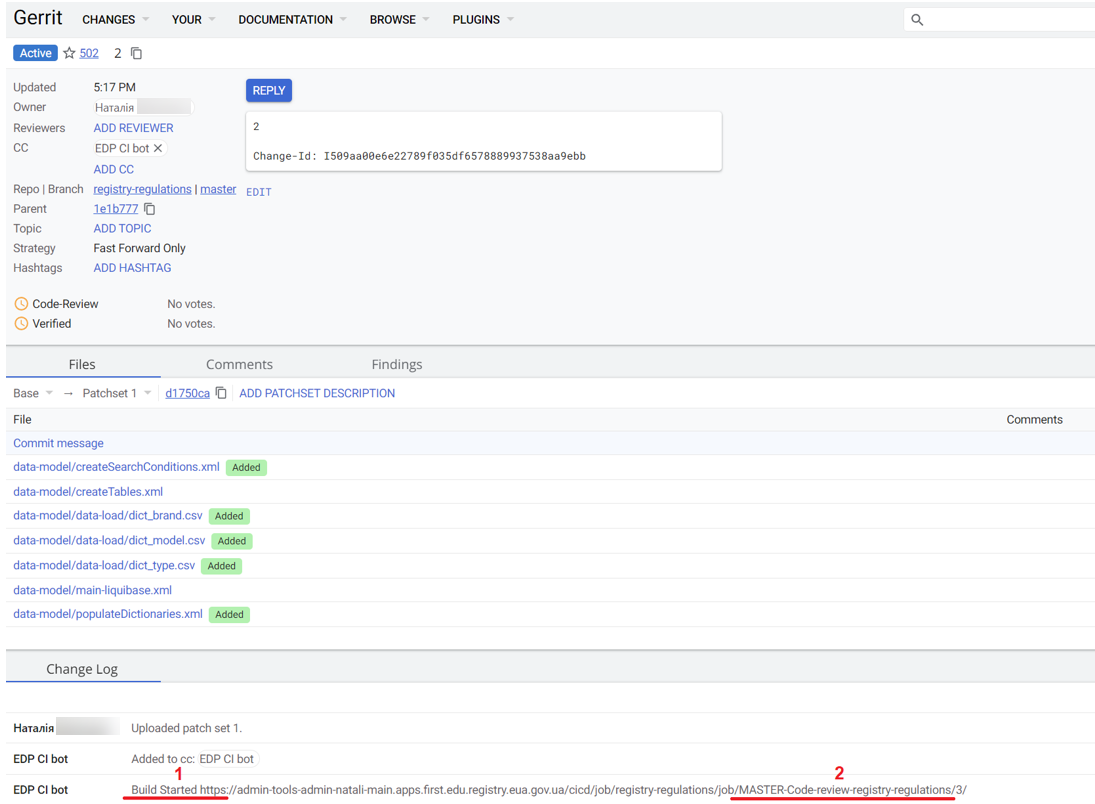
Якщо збірка завершиться успішно, статус зміниться на SUCCESS.
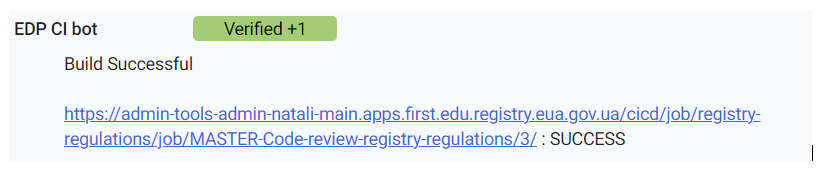
| У разі виникнення помилок необхідно провести дебаг, описаний у розділі нижче: Відстеження помилок під час збірки регламенту у сервісі Jenkins. |
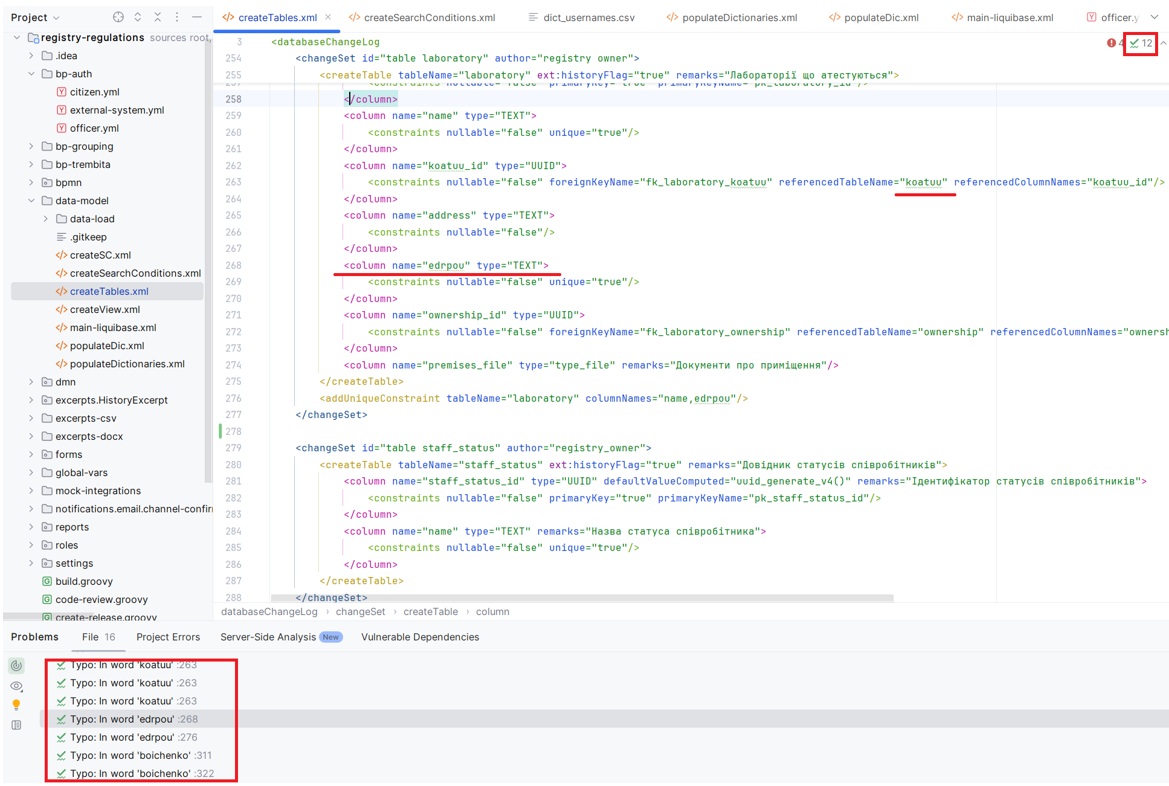
Середовище розробки IntelliJ IDEA також відстежує дублювання унікальних ідентифікаторів і підкреслює місця помилок. Щоб побачити причину помилки, можна навести курсор на підкреслене червоним місце і з’явиться опис помилки. Також справа з’являється знак оклику у червоному кружечку і поруч кількість помилок, яка є у файлі. При натисканні на знак оклик знизу з’являється консоль з описом помилки:
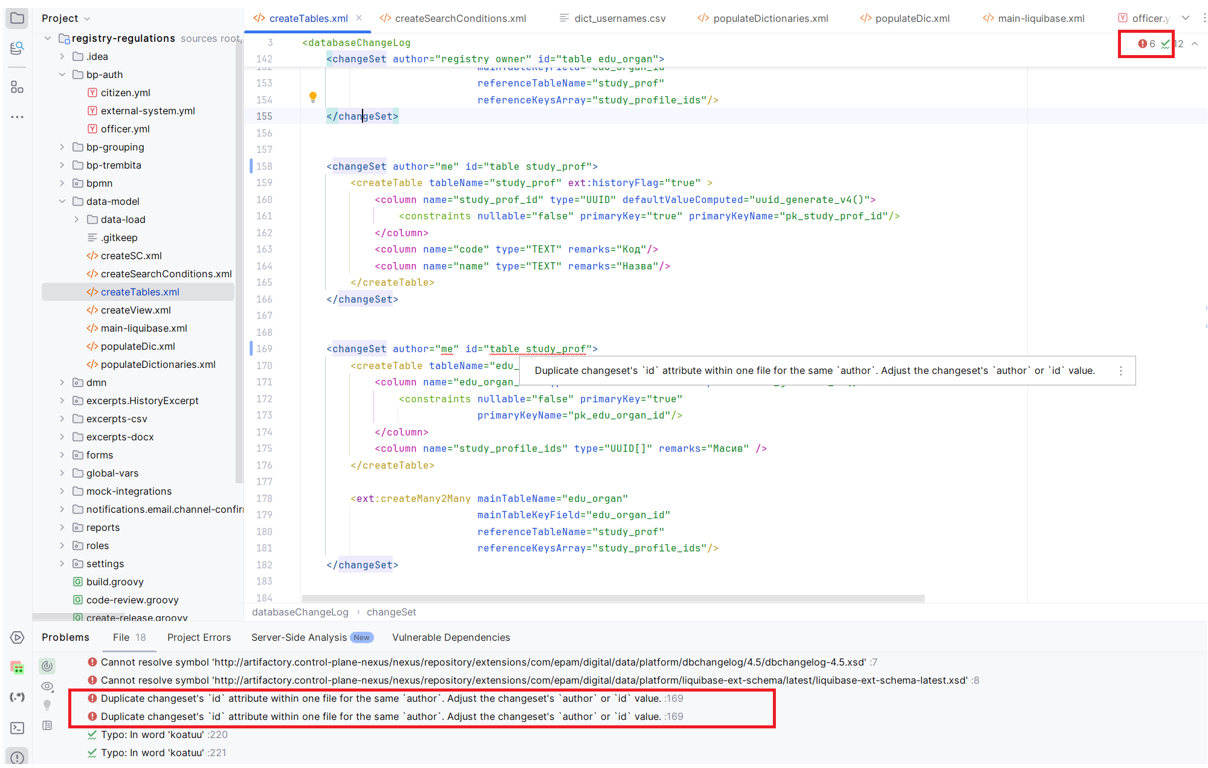
Завдяки вбудованому аналізатору кода IntelliJ IDEA відслідковує синтаксичні помилки і підкреслює їх зеленим, детальніше подивитися у консолі помилки можна натиснувши на зелену галочку, поряд з якою вказано загальну кількість синтаксичних помилок:
2.2. pgAdmin
Платформа pgAdmin надає можливість переглядати SQL-код і створювати SQL-запити до бази даних.
| Детальніше про підключення до pgAdmin можна дізнатися на сторінці Взаємодія з базою даних реєстру через pgAdmin. |
Для перегляду створених таблиць:
-
Виберіть таблицю, далі натисканням правої клавіші миші виберіть . В результаті автоматично згенерується скрипт, який при запуску виведе на екран усі згенеровані поля таблиці.
-
Натисніть кнопку
Execute: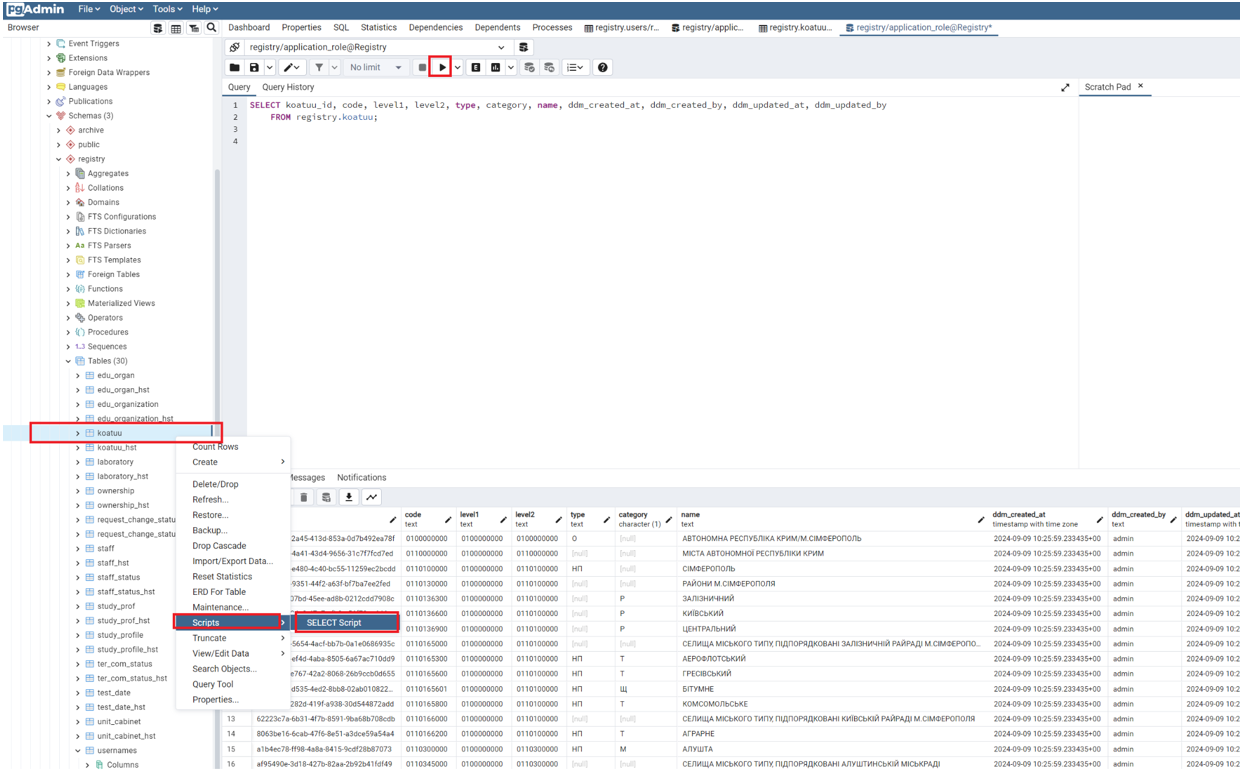
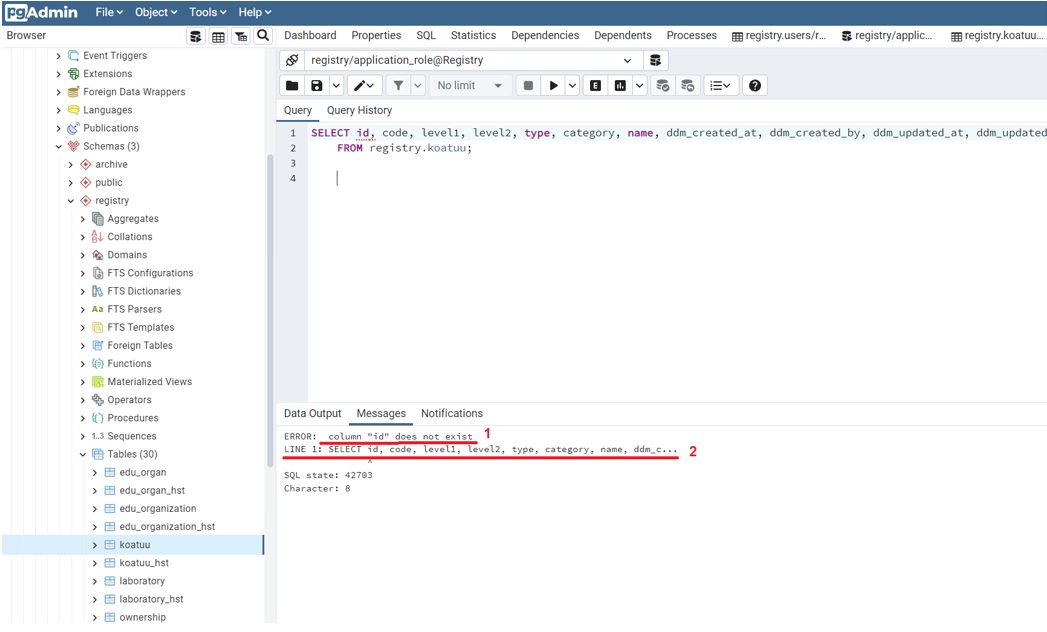
За допомогою pgAdmin можна відстежувати коректність запису даних до бази даних. Якщо у скрипті присутня помилка, її буде відображено внизу з детальним описом:
-
Яка саме помилка
-
Місце, де сталася помилка
3. Відстеження помилок під час збірки регламенту у сервісі Jenkins
Збірка регламенту реєстру проходить в декілька етапів на різних пайплайнах, і на кожному з них можливе виникнення помилок.
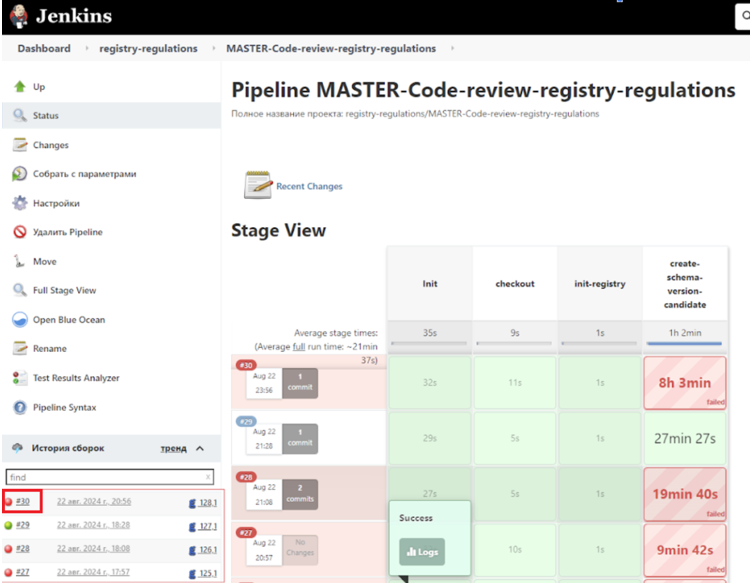
У разі виникнення помилки під час збірки регламенту, етап, на якому сталася помилка, буде підсвічено червоним кольором. Для отримання більш детального опису помилки та визначення способу її усунення необхідно виконати наступні кроки:
-
Ліворуч знизу екрану, в історії збірок, оберіть відповідний номер збірки, де сталася помилка — поруч із номером збірки буде червоне коло, що вказує на помилку.
-
У новому вікні ліворуч відкрийте Console Output.
-
Перегляньте детальний опис помилки у нижній частині сторінки:
-
де сталася помилка;
-
яка саме помилка;
-
у якому рядку сталася помилка (якщо це помилка синтаксична або виникла в процесі розгортання сутностей із
.xml-файлів).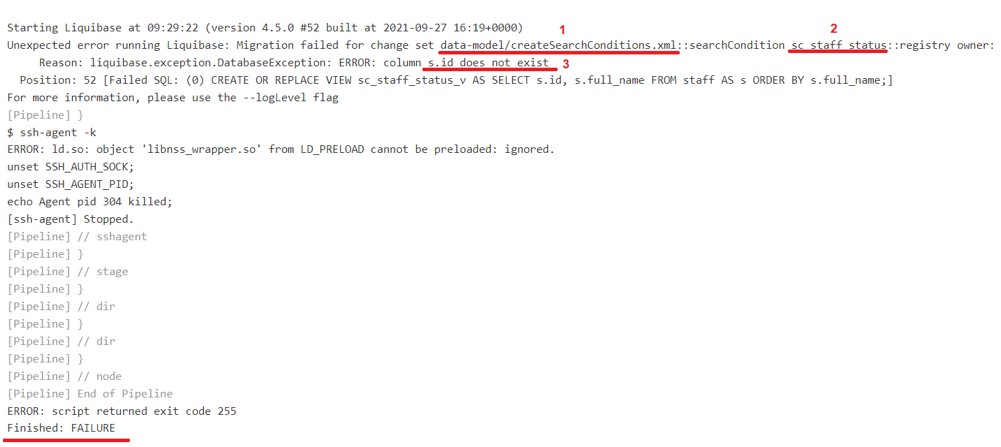
Вище можна побачити приклад помилки, який стався на етапі валідації коду:
-
1 — показує назву папки і файлу, де сталася помилка: тека
data-model, файлcreateSearchConditions.xml; -
2 — показує назву
SearchCondition, де сталася помилка:sc_staff_status; -
3 — показує, яка сама помилка: в таблиці не існує поля
id.
-
-
При виникненні помилок на різних етапах збірки, в логах додатково можуть з’явитись посилання на детальний опис помилки, яку необхідно опрацювати.
Наприклад, в логах основної збірки з’являється посилання на помилку, що виникла на етапі роботи пайплайну MASTER-Build-registry-regulations-data-model. Ви можете скористатися посиланням, щоб побачити причину виникнення помилки:
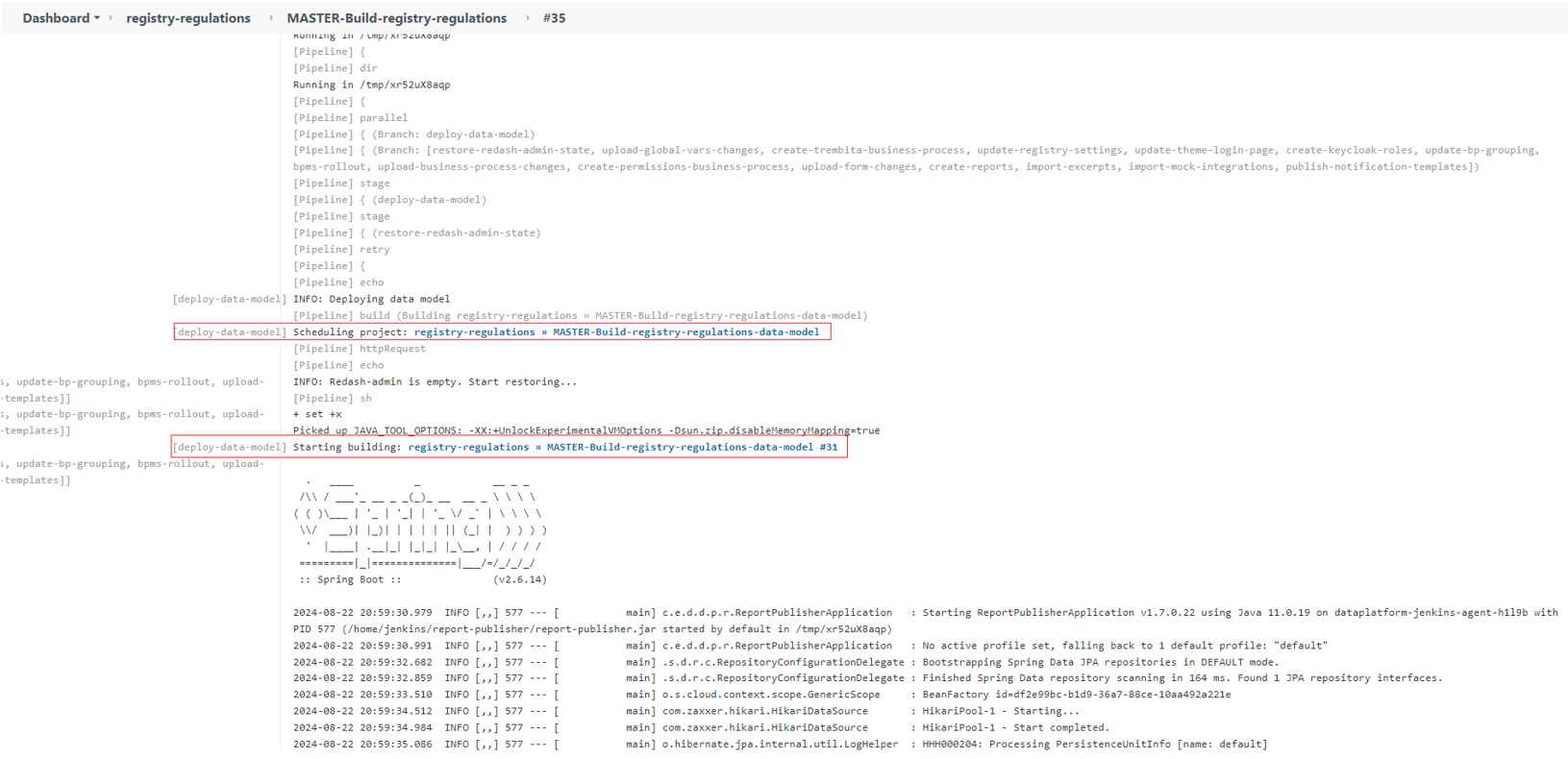
Щоб виправити помилку, виконайте наступні дії:
-
Скасуйте останній коміт.
-
Усуньте причину помилки.
-
Повторно виконайте внесення змін (
git add,git commit,git push).
| Найпоширеніші помилки й способи їх усунення описані на сторінці Типові помилки та алгоритм їх усунення. |
4. Дебаг Groovy-скриптів
У процесі розробки бізнес-процесу розробник може додавати скриптові задачі до процесу, написані мовою Groovy, а також використовувати у скриптах JUEL-функції. Можливою проблемою для розробника може стати опрацювання результату, отриманого на попередньому етапі. Оскільки результат опрацювання є специфічного типу, який підтримує Camunda (наприклад, клас Camunda SpinListImpl), цей результат необхідно опрацювати або привести до іншого Java-типу, або дістати конкретне значення.
4.1. Вивід даних Groovy-скрипта у консоль
Одним із методів дебагу на цьому етапі є вивід отриманих даних у консоль.
Для прикладу розглянемо опрацювання результату виконання сервісної задачі Пошук сутностей у фабриці даних: Search for entities in data factory.
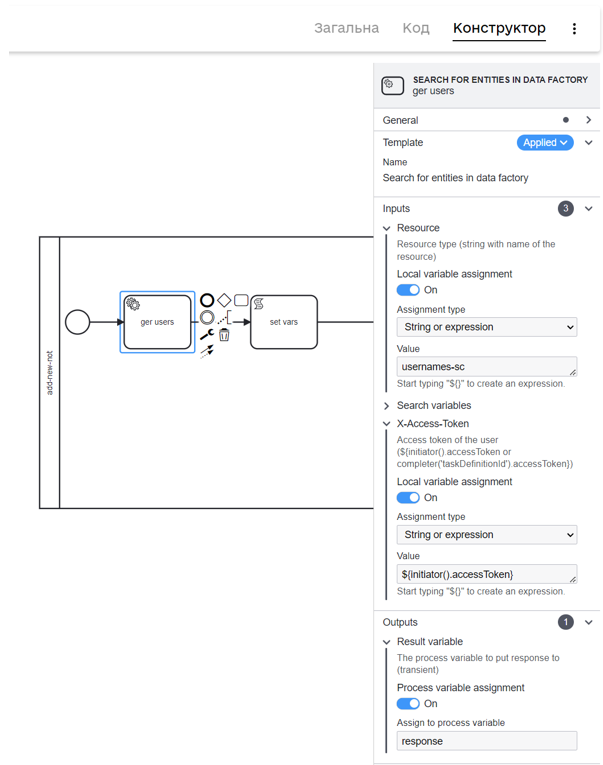
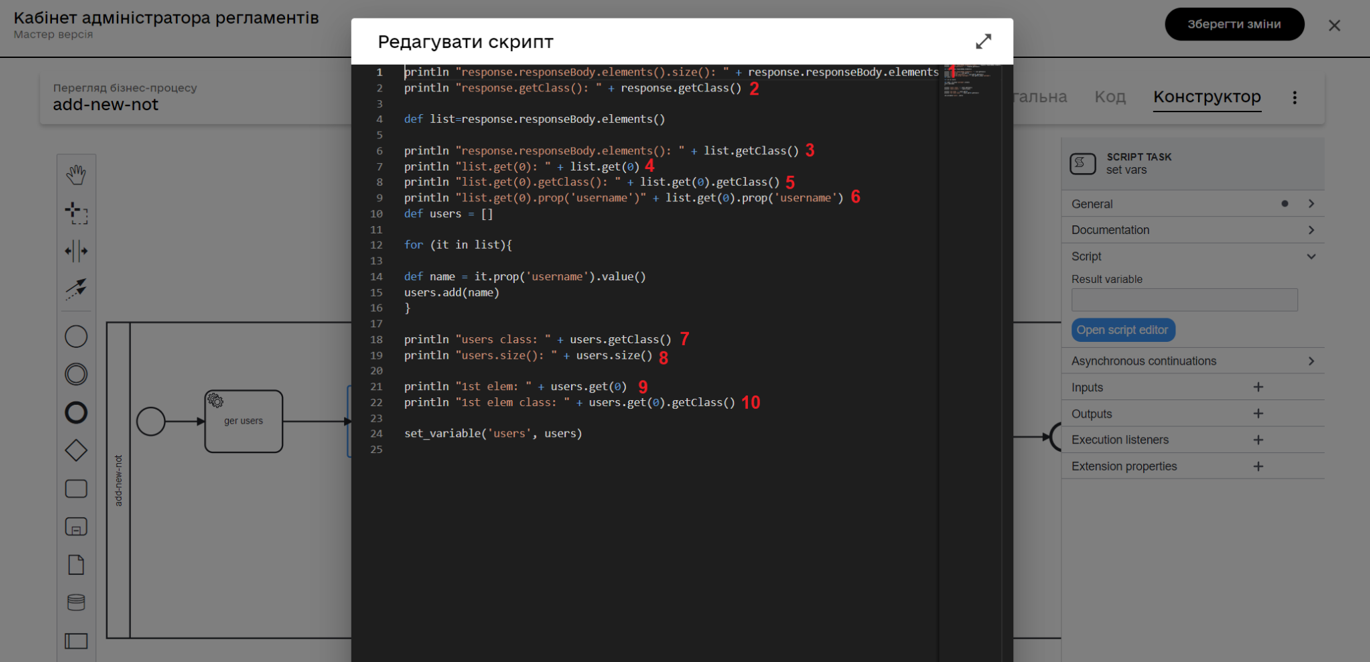
У скриптовій задачі за допомогою функції println виведіть у консоль наступні параметри:
-
Кількість елементів, які отримали після виконання сервісної задачі Search for entities in data factory.
-
Назва класу змінної
response— результат виконання сервісної задачі. -
Назва класу елементів у змінній
response. -
Значення першого елементу змінної
response(зберігається у форматі ключ-значення). -
Назва класу першого елементу змінної
response. -
Збереження значення з ключем "userName" у першому елементі змінної
response. -
Назва класу змінної
users. -
Кількість елементів, збережених у змінній
users. -
Значення першого елементу у змінній
users. -
Назва класу першого елементу у змінній
users.
| Мова програмування Groovy розроблена для платформи Java, отже вона також підтримує всі команди й синтаксис мови Java, тому можна використовувати команди зі стандартної бібліотеки Java. |
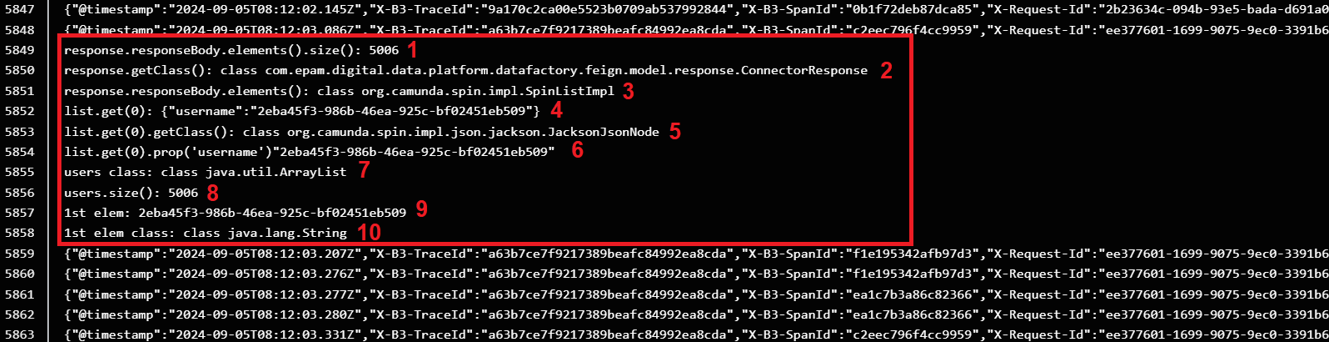
Для перегляду виведених даних у консоль, оберіть поду bpms (детальніше про поди див. розділ OpenShift Pods нижче) і перейдіть на вкладку Logs, щоб мати можливість переглянути у консолі всі значення, які були прописані в скриптовій задачі:
4.2. Робота з Groovy-скриптами у середовищі розробки
Іншим способом дебагу є створення Groovy-скриптів у середовищі розробки, наприклад, в IntelliJ IDEA. Такий метод дебагу дозволяє швидко вносити велику кількість виправлень до коду й одразу отримувати результати роботи з кодом.
| Важливо правильно налаштувати середовище розробки, вказавши всі необхідні залежності й їх версії, які є актуальними для платформи. Ви можете переглянути актуальний для платформи POM-файл із необхідними залежностями й перенести всі налаштування у свій проєкт. |
Для налаштування середовища розробки IntelliJ IDEA виконайте наступні кроки:
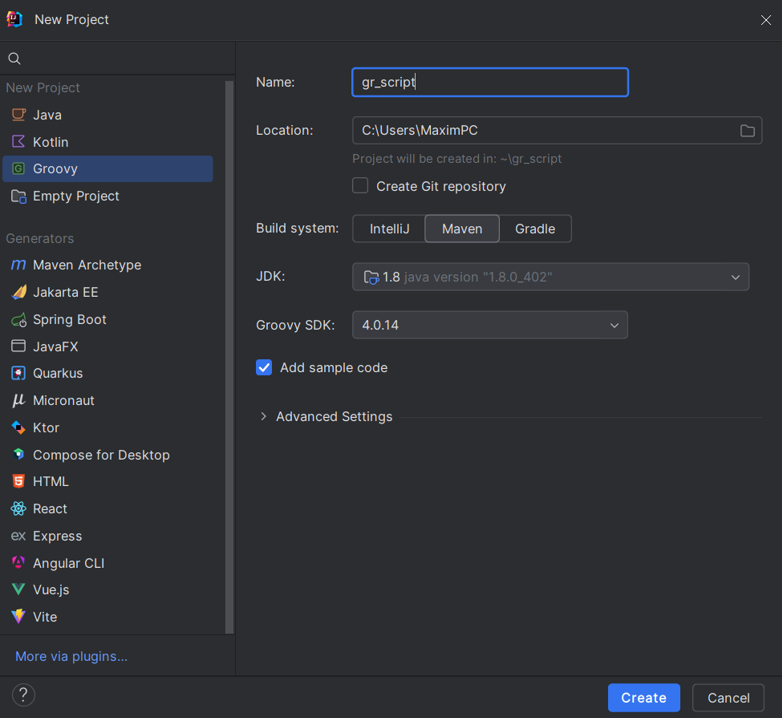
-
Створіть новий проєкт Groovy із фреймворком Maven.
-
Налаштуйте
propertiesтаdependenciesу POM файлі проєкту відповідно до файлу-прикладу. Усі версії мають бути такими ж, як і у файлі-прикладі.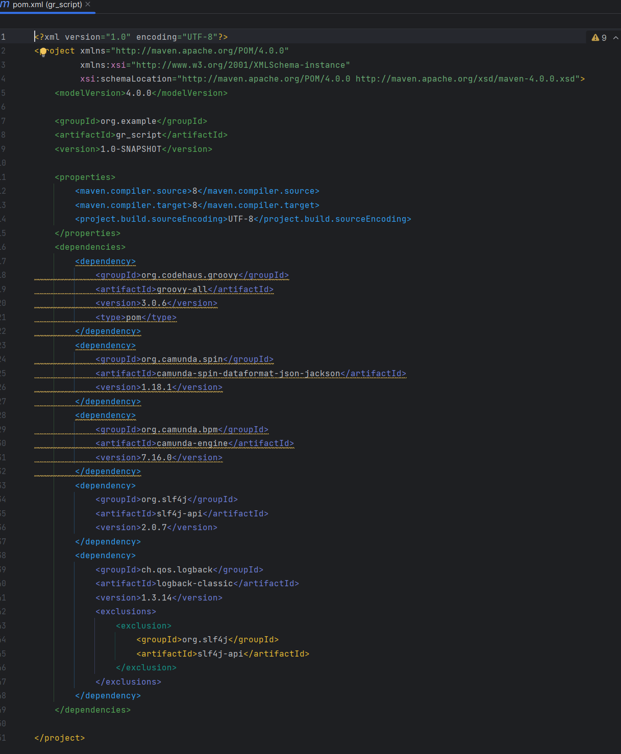
-
У папці створіть новий Groovy Script, введіть ім’я файлу й натисніть Enter.
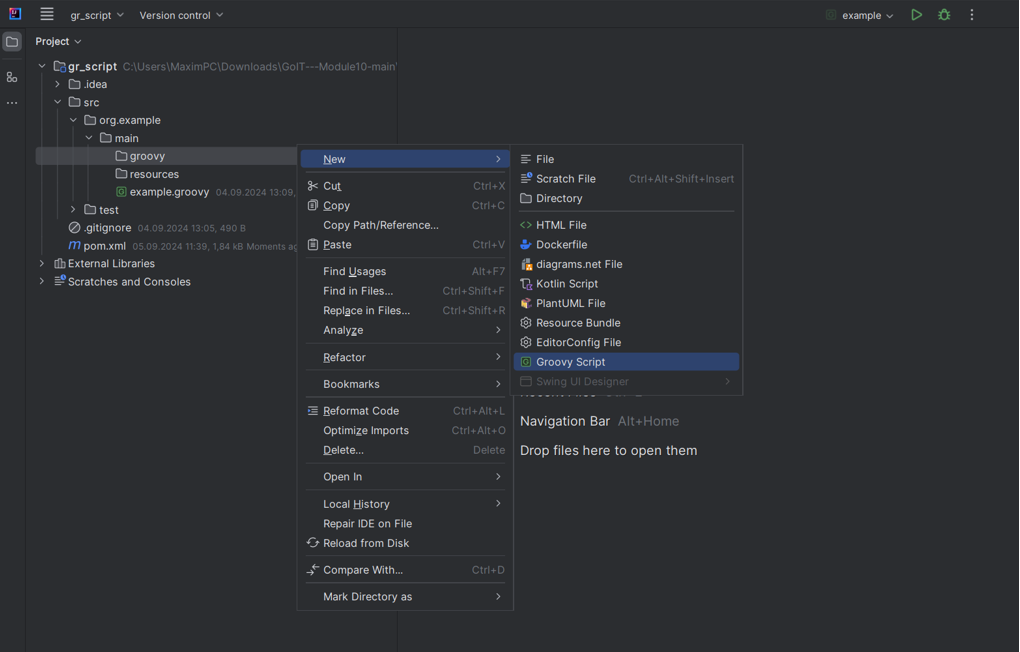
-
Перенесіть скрипт у створений файл, який необхідно протестувати, внесіть усі необхідні дані. Як зразок використайте приклад конвертації даних із JSON у map ключів-значень.
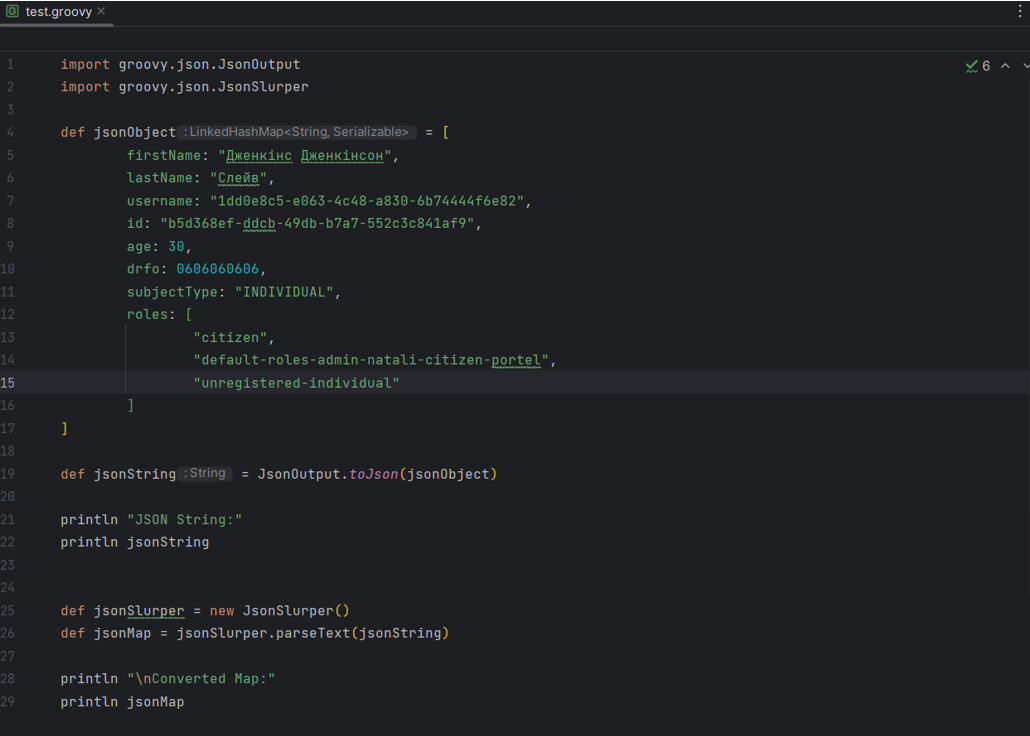
-
Запустіть файл, результати виконання скрипта будуть виведені у консоль.
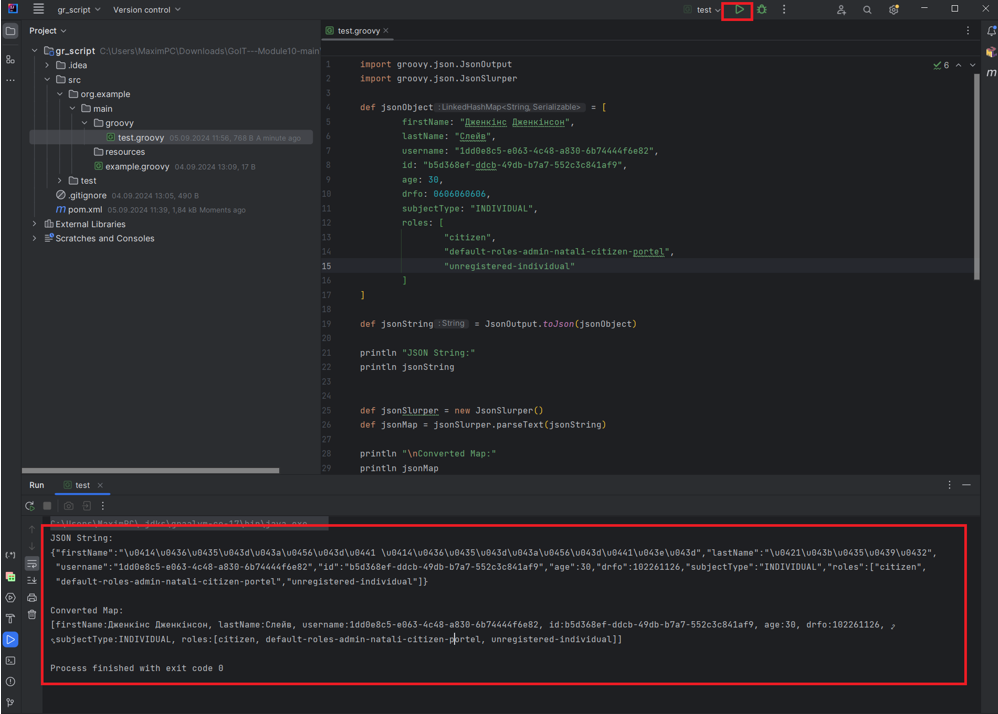
Тестування скрипта в середовищі розробки дає можливість швидко перевірити необхідний скрипт, виявити помилки та виправити їх.
5. Відстеження помилок при розробці бізнес-процесу у Camunda
| При створенні бізнес-процесів дотримуйтеся вимог до розробки й для уникнення помилок сумісності вашої бізнес-моделі з платформними вимогами й налаштуваннями, рекомендується початково створювати бізнес-процес у Кабінеті адміністратора. |
5.1. Налаштування плагіна BPMN Linter для Camunda Modeler
Для валідації створення й налаштування бізнес-процесу у десктопному застосунку Camunda Modeler увімкніть плагін BPMN Linter. Цей плагін перевіряє правильність налаштування діаграми бізнес-процесу і підсвічує помилки, якщо вони є:
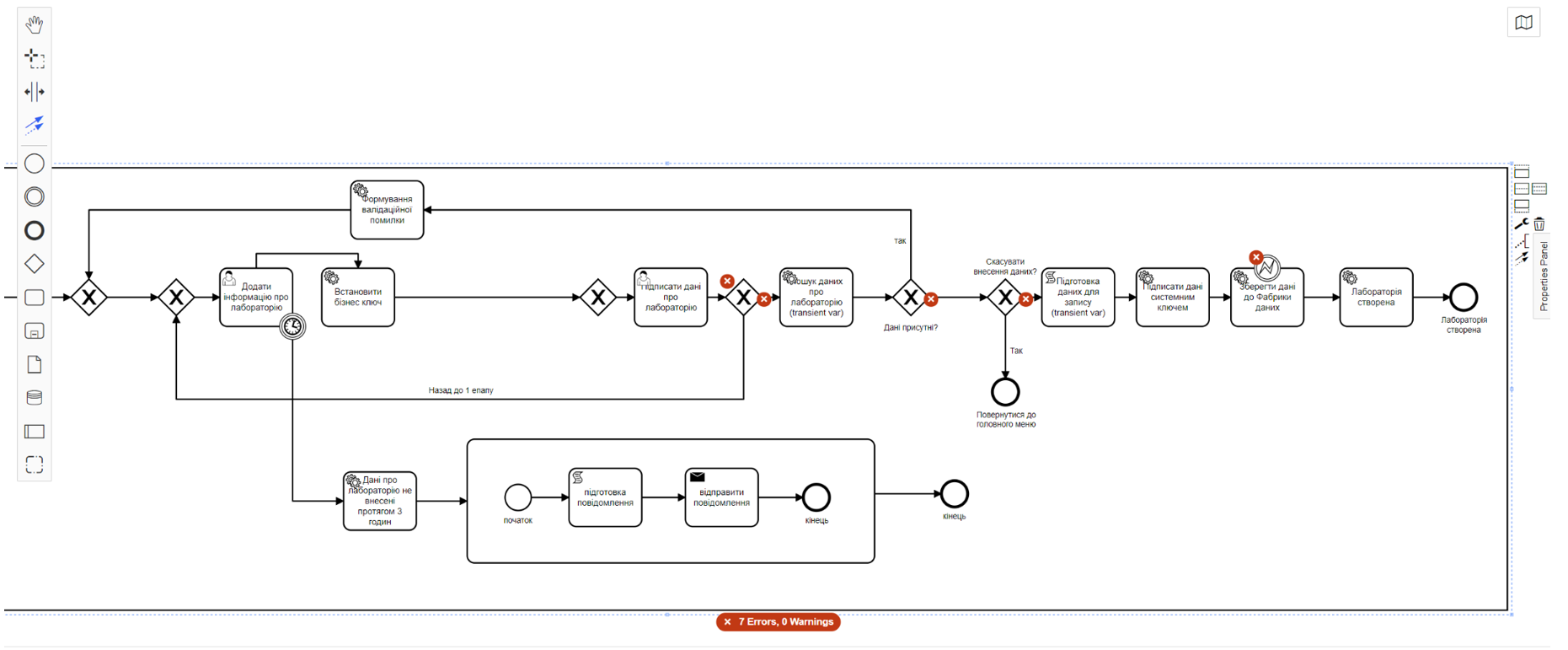
При наведенні на кожен із червоних хрестиків, що з’явились на елементах бізнес-процесу, можна отримати інформацію про помилку:
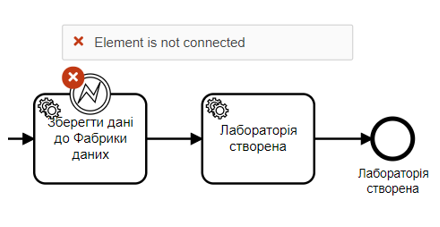
Основні помилки, які підсвічує плагін BPMN Linter:
-
Відсутність початкової або кінцевої події.
-
Відсутність налаштувань на гілках, коли можливий сценарій розгортання декількох варіантів продовження процесу.
-
Відсутність з’єднання між елементами.
-
Відсутність назви елемента.
5.2. Дебаг бізнес-процесу у Кабінеті адміністратора регламентів
Існують обмеження на використання деяких зарезервованих слів під час створення назв бізнес-процесів. Наприклад, не можна використовувати слова get, set, user у будь-якій комбінації для бізнес-назви та службової назви процесу. Такі обмеження легше відстежувати саме під час створення бізнес-процесу: створіть у Кабінеті адміністратора регламенту новий бізнес-процес, додайте в конструкторі елементи Pool/Participant, start event та end event, налаштуйте кожен із них і збережіть бізнес-процес:
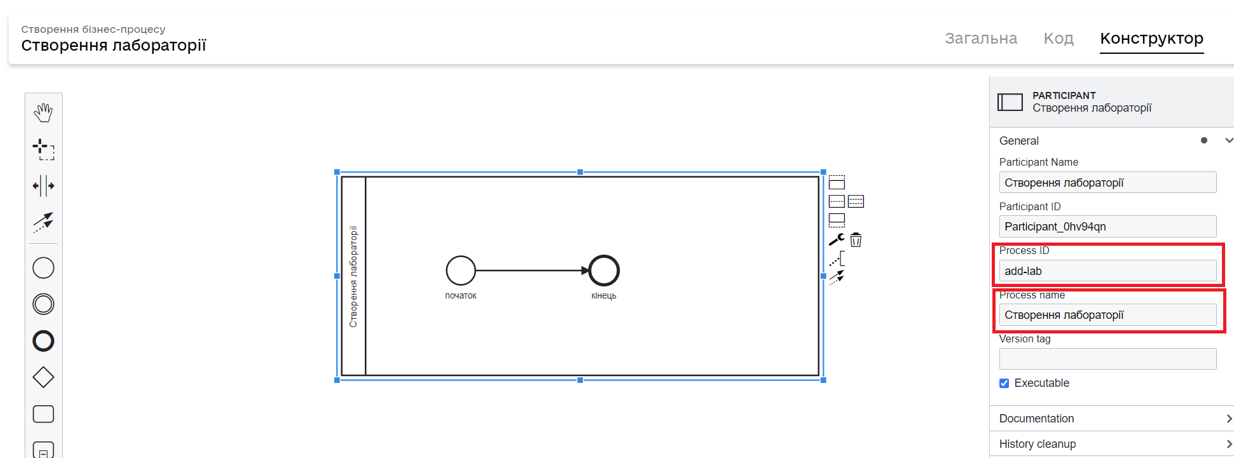
Виділені поля є обов’язковими для заповнення. Адже саме ці два поля автоматично додаються як службова назва і бізнес-назва процесу в Кабінеті адміністратора при створенні бізнес-процесу:
5.3. Camunda Cockpit
Camunda Cockpit — це інструмент для моніторингу та адміністрування процесів, що створюються у застосунку Camunda. Ця платформа застосовується для автоматизації бізнес-процесів і надає можливість швидко відстежувати роботу бізнес-процесів.
Основні функції Camunda Cockpit:
-
Можливість переглядати статус виконання бізнес-процесів у реальному часі і відстежувати, які етапи процесу вже виконані, де є затримки або проблеми.
-
Можливість швидко знаходити та усувати помилки, які виникають під час виконання різних процесів.
-
Можливість переглядати деталі виконаних завдань, включаючи історію процесу, та аналізувати їх продуктивність.
-
Можливість контролювати процеси, зупиняти і завершувати завдання на різних етапах бізнес-процесу.
Для початку необхідно налаштувати доступ до Camunda Cockpit, після чого розробнику будуть доступні всі можливості Camunda Cockpit для адміністрування бізнес-процесів.
За замовчуванням у Camunda налаштовано 3 спроби для виконання процесу з інтервалом у 5 хвилин. Якщо у процесі є помилка або процес виконується занадто довго, система може інтерпретувати це як невдачу і запускати його знову.
6. Додаткові можливості дебагу
6.1. Chrome DevTools
Chrome DevTools (інструменти розробника) надає можливість відстежувати помилки у ході виконання бізнес-процесу.
| Детальніше про помилки на етапі розробки бізнес-процесу див. на сторінці Типові помилки та алгоритм їх усунення. |
Найпершим кроком для виявлення місця, де сталася помилка, є відстеження запитів і відповідей, якими обмінюються браузер та сервер. Для запуску DevTools на будь-якому місці у відкритому вікні натисніть правою клавішею миші та виберіть “Подивитися код”. У консолі, що відкрилась, перейдіть на вкладку Network → Fetch/XHR та оберіть подію, на якій сталась помилка (поруч з назвою буде червоний кружечок із хрестиком):
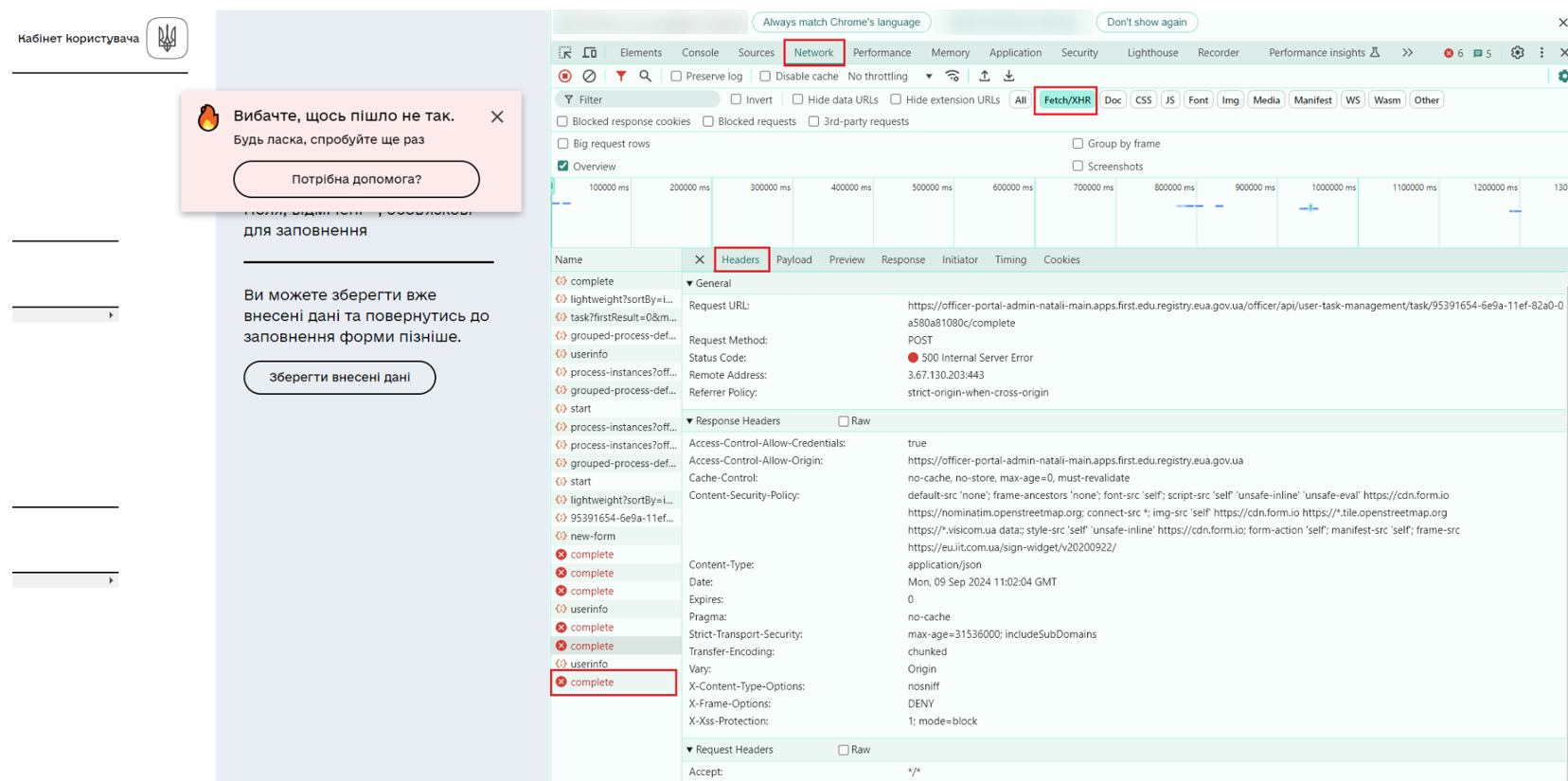
У вкладці Headers буде відображено список усіх завантажених сторінкою ресурсів, а також діагностична інформація щодо кожного з них. Для більш детального опису помилки перейдіть на вкладку Response:
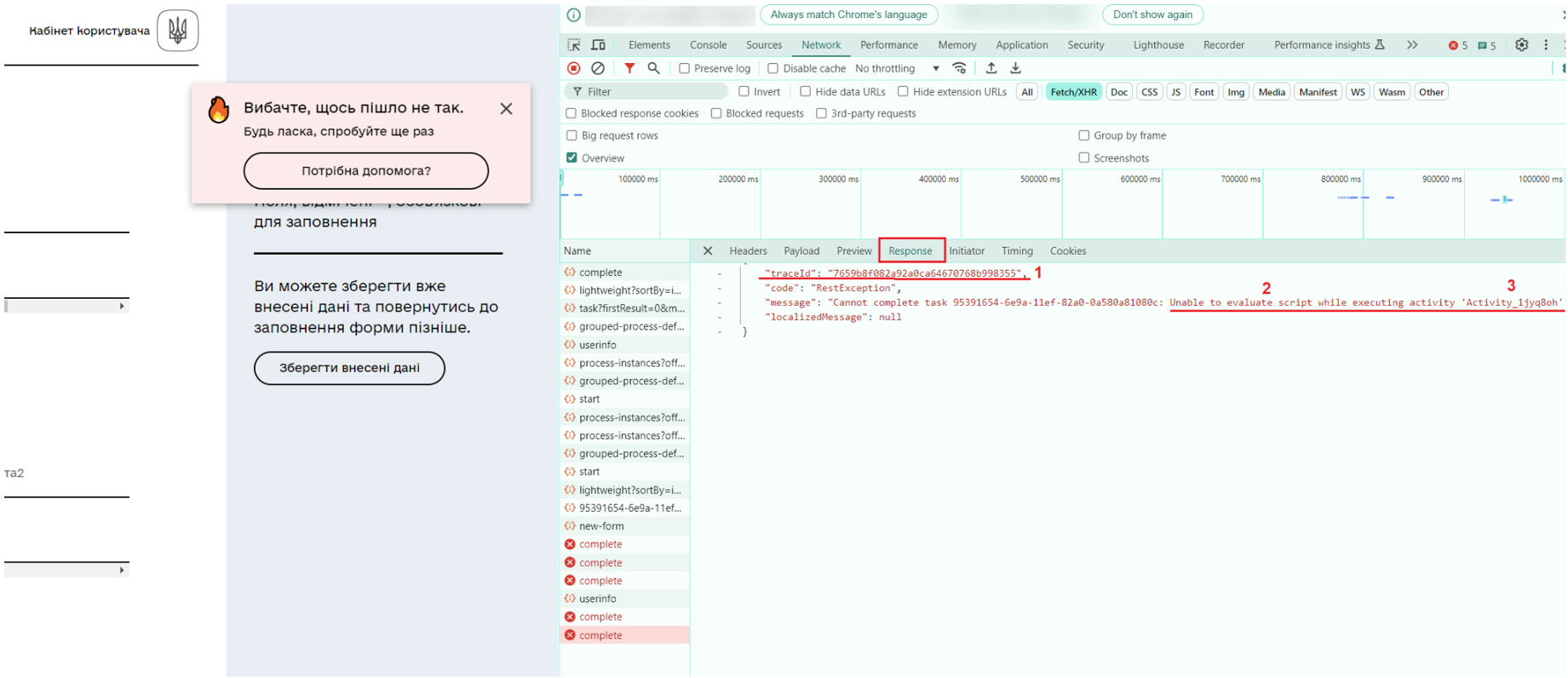
На цій вкладці відображається:
-
traceId— унікальний ідентифікатор запиту у системі трейсингу, який дозволяє в деталях простежити історію виконання запиту. -
Опис помилки.
-
Назва елемента, де сталася помилка.
6.2. OpenShift Pods
Платформа OpenShift надає можливість відстежувати всі процеси, що запускаються в конкретному поді (Pod).
Основні поди, які необхідні для відстежування помилок (xxx у назві — це змінний код, який залежить від збірки регламенту):
-
admin-portal-xxx— под відповідає за роботу Кабінету адміністратора регламенту, -
citizen-portal-xxx— под відповідає за роботу Порталу отримувача послуг, -
officer-portal-xxx— под відповідає за роботу Кабінету посадової особи, -
gerrit-xxx— под відповідає за роботу Gerrit, -
jenkins-xxx— под відповідає за роботу Jenkins, -
bpms-xxx— под відповідає за роботу Camunda Engine.
Для відстежування процесу у поді на OpenShift виконайте наступні кроки:
-
В інтерфейсі OpenShift виберіть ваш реєстр і відкрийте розділ Pods.
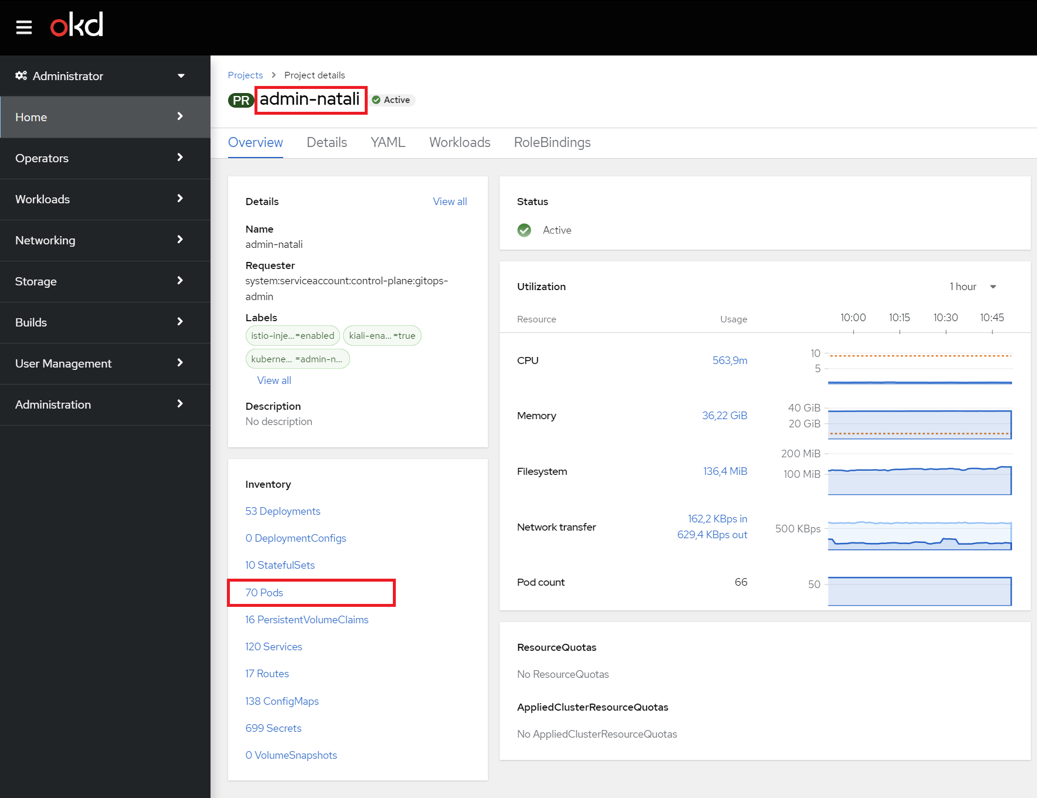
-
У пошуку введіть назву пода, наприклад,
bpms, і натисніть на нього.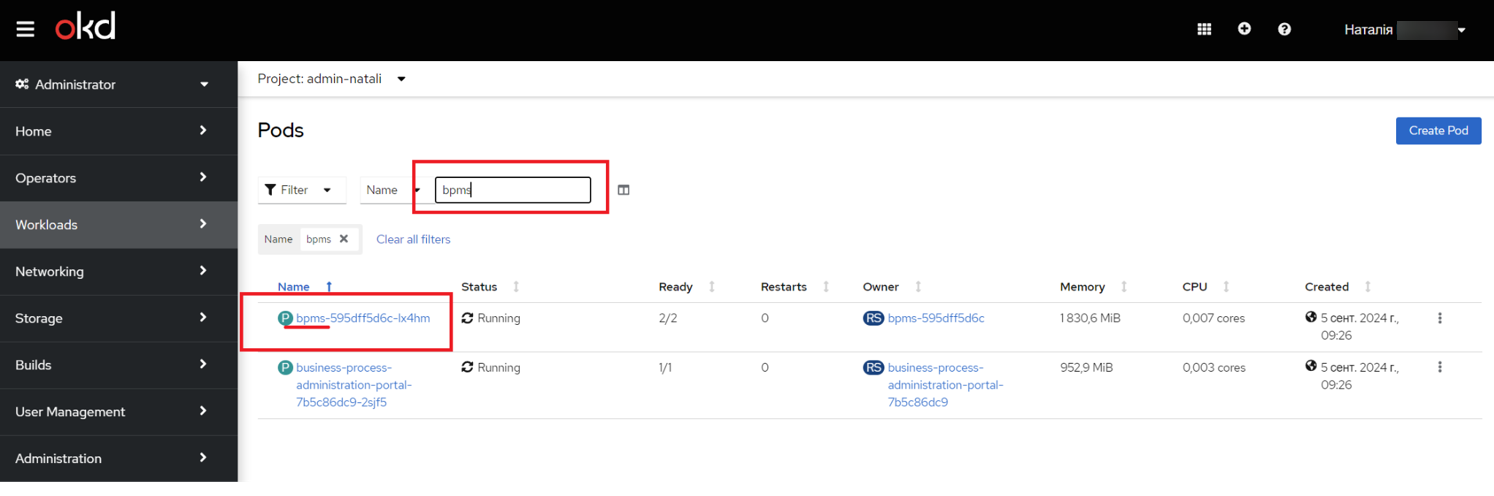
-
Перейдіть на вкладку Logs і натисніть Resume stream (за потреби), щоб завантажити останні логи.
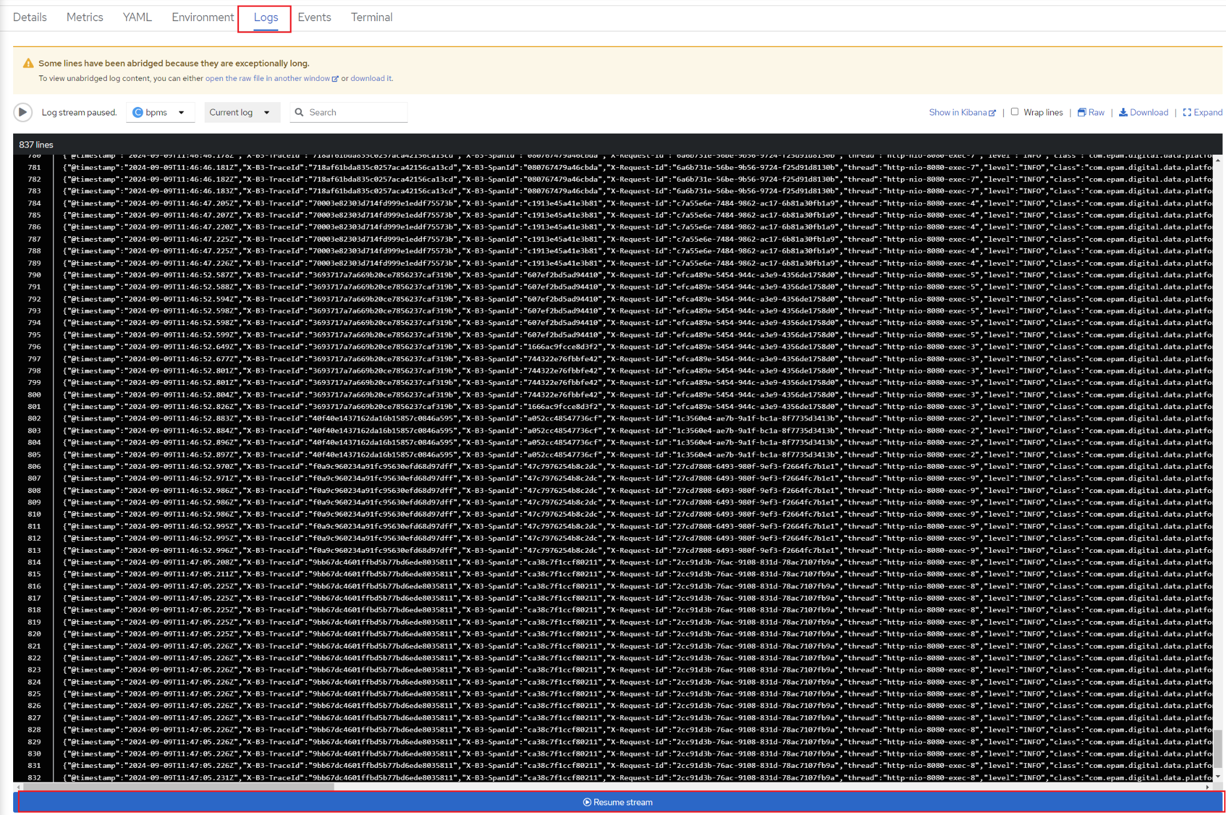
У нижній частині сторінки буде показана помилка:
-
Над першою червоною лінією відображається загальний текст повідомлення: неможливо виконати дію елемента
'Activity_1jyq8oh'(в Camunda є можливість знайти елемент за його назвою). -
Над другою червоною лінією відображається вже сама помилка: не існує властивості (у цьому випадку — змінної)
hello.

6.3. Kibana
Kibana — це інструмент візуального інтерфейсу, який дозволяє візуалізувати та створювати інформаційну панель над даними журналу подій платформи. Для можливості дебагу у Kibana необхідно створити Index Pattern та налаштувати фільтри.
| Детальніше про налаштування Kibana можна ознайомитись на сторінці: Завдання 8. Логування подій (Kibana). |
У результаті налаштування Index Pattern та фільтрів за помилкою буде відображатися загальний опис помилок. Додатково можна налаштувати вивід лише повідомлення опису помилки, для цього з правого боку виберіть фільтр structured.exception.message:
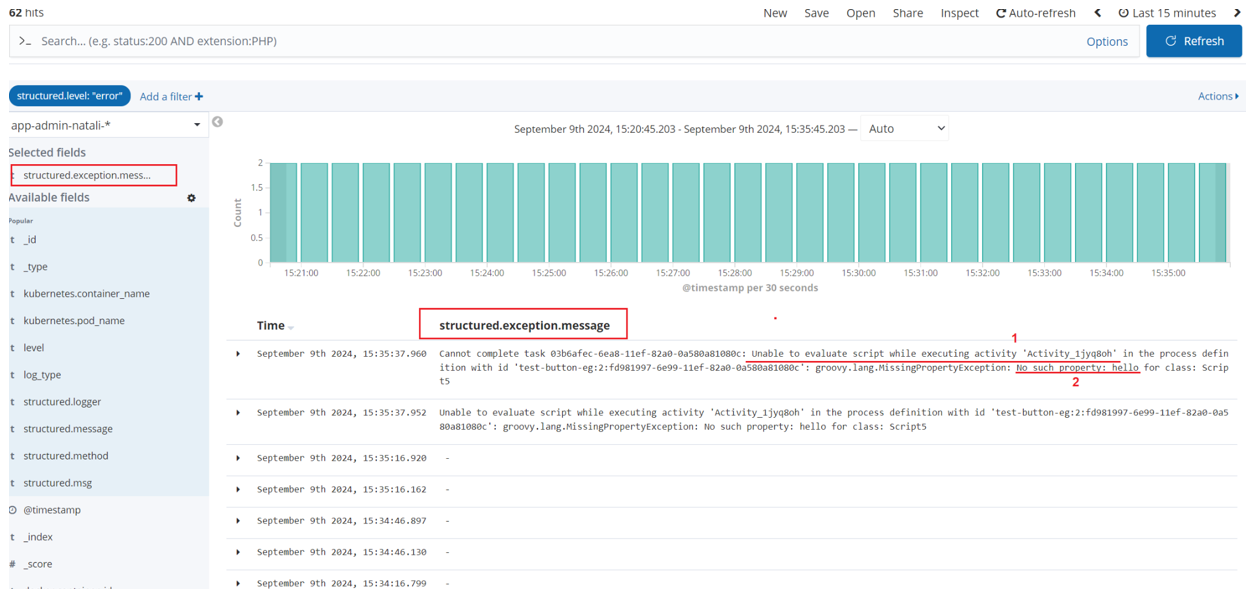
Тепер у стовпці structured.exception.message буде відображатися детальний опис помилки:
-
Назва елементу, в якому сталася помилка.
-
Яка саме помилка: не існує властивості (тут — змінної)
hello.
Також знайти потрібну помилку можна за допомогою traceId.
-
Скопіюйте значення
traceIdіз Chrome DevTools та вставте його у пошуковий рядок. Для детального перегляду помилки рекомендується вибрати фільтрstructured.exception.message. -
Для відображення деталей помилки натисніть на прапорець, помічений цифрою 1, і прокрутіть сторінку трохи вниз:
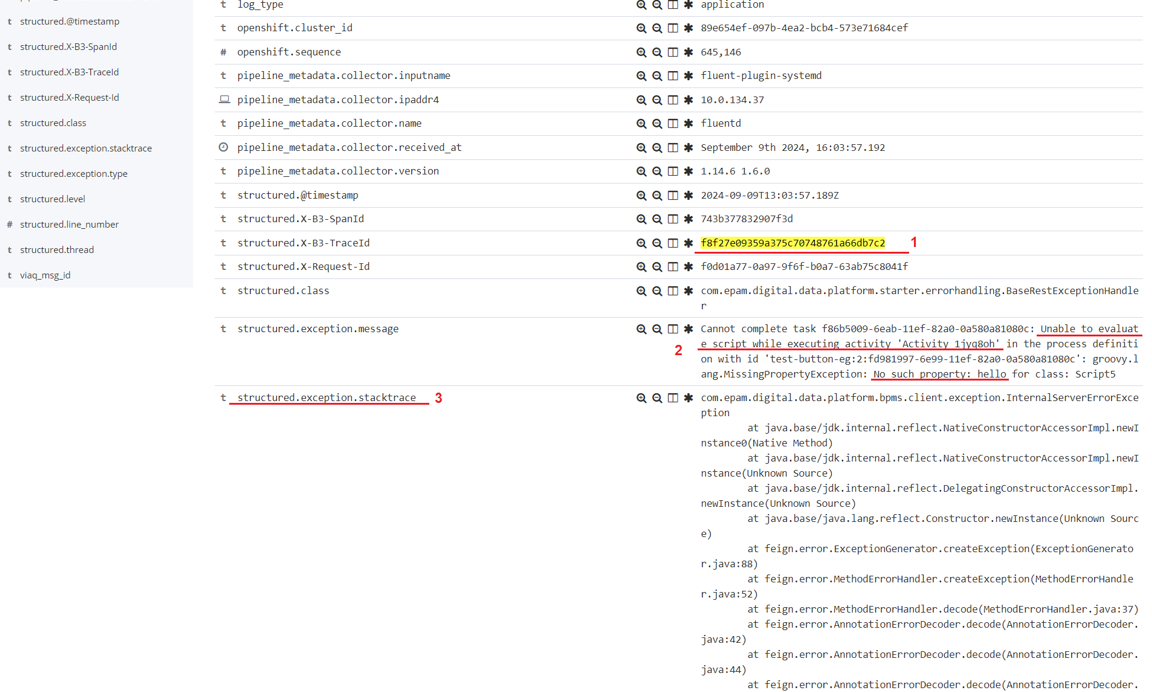
-
Значення
traceId. -
Детальний опис помилки.
-
java stacktraceпомилки.