Ceph cluster maintenance and related operations
| 🌐 This document is available in both English and Ukrainian. Use the language toggle in the top right corner to switch between versions. |
The Platform uses the rook-operator to deploy and manage the openshift-storage Ceph cluster. This document provides best-practice recommendations for maintaining the Ceph cluster and related operations to ensure system stability and data integrity.
1. Manual deep scrubbing
Disable automatic deep scrubbing after deploying the Platform to avoid performance impact during peak hours. However, periodically running deep scrubbing is critical for verifying object integrity. Learn how to re-enable deep scrubbing, trigger it manually, and run it efficiently.
|
❗ Run deep scrubbing manually at least once every few weeks, depending on your SLA and data criticality. Schedule it during low-load periods — e.g., weeknights or weekends. No formal maintenance window is required if there’s no impact on critical services. 📌 Avoid PG backlog, where Placement Groups go unchecked for too long.
In large clusters, run daily with limited concurrency ( |
1.1. Enabling deep scrubbing
To start deep scrubbing manually, first remove the nodeep-scrub flags from all pools and then initiate the necessary Ceph CLI commands from the rook-operator pod in the openshift-storage project.
nodeep-scrub flags from all poolsfor pool in $(ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls); do
ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool set "$pool" nodeep-scrub false
doneceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls detailceph osd --conf=/var/lib/rook/openshift-storage/openshift-storage.config deep-scrub all# For a specific OSD
ceph osd --conf=/var/lib/rook/openshift-storage/openshift-storage.config deep-scrub 0
# For all pools
for pool in $(ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls); do
ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool deep-scrub "$pool"
done1.2. Speeding up deep scrubbing when backlog exists
If many PGs are waiting for deep scrubbing, you can speed up the process by:
-
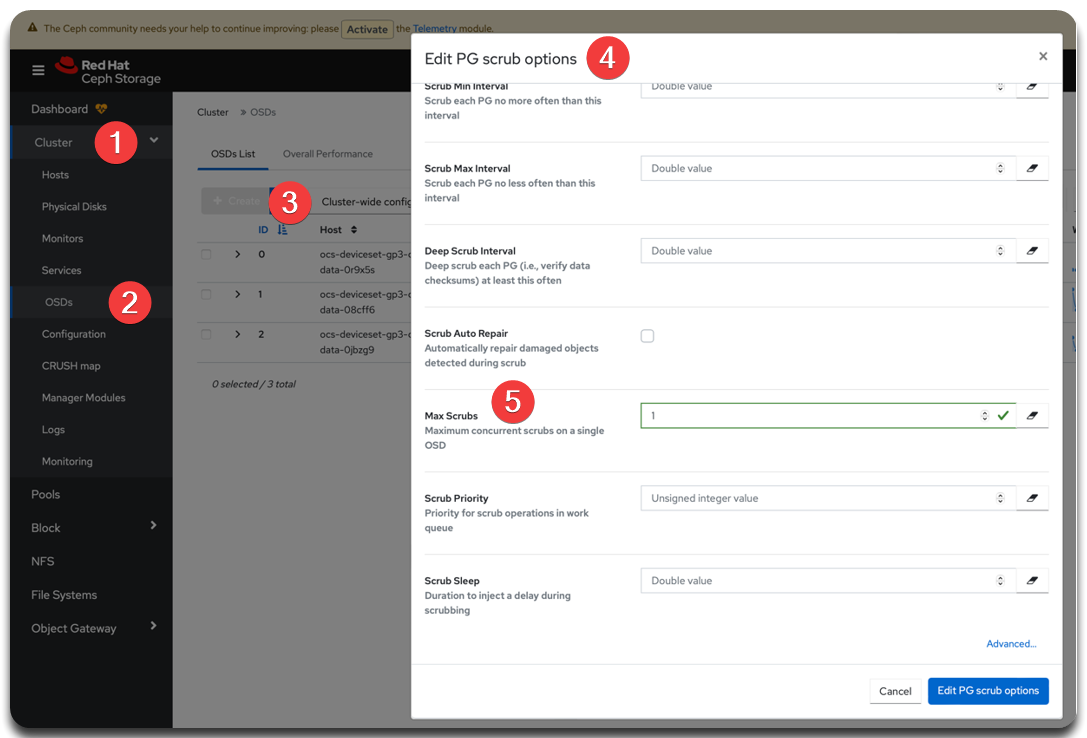
Temporarily increasing the number of concurrent scrubbing processes, up to 4.
OR
-
Extending the maintenance window and running deep scrubbing manually during weeknights.
osd_max_scrubs to 4ceph config --conf=/var/lib/rook/openshift-storage/openshift-storage.config set osd osd_max_scrubs 4|
After the operation, revert ➡️ See more in Concurrent scrubbing settings. |
2. Monitoring scrubbing status
Use this section to monitor the health and performance of the scrubbing process. You’ll learn how to check cluster-wide scrubbing status, track deep scrubbing execution, and review Placement Group logs. These steps help you detect issues early and maintain data consistency.
2.1. Monitoring via Grafana Web Interface
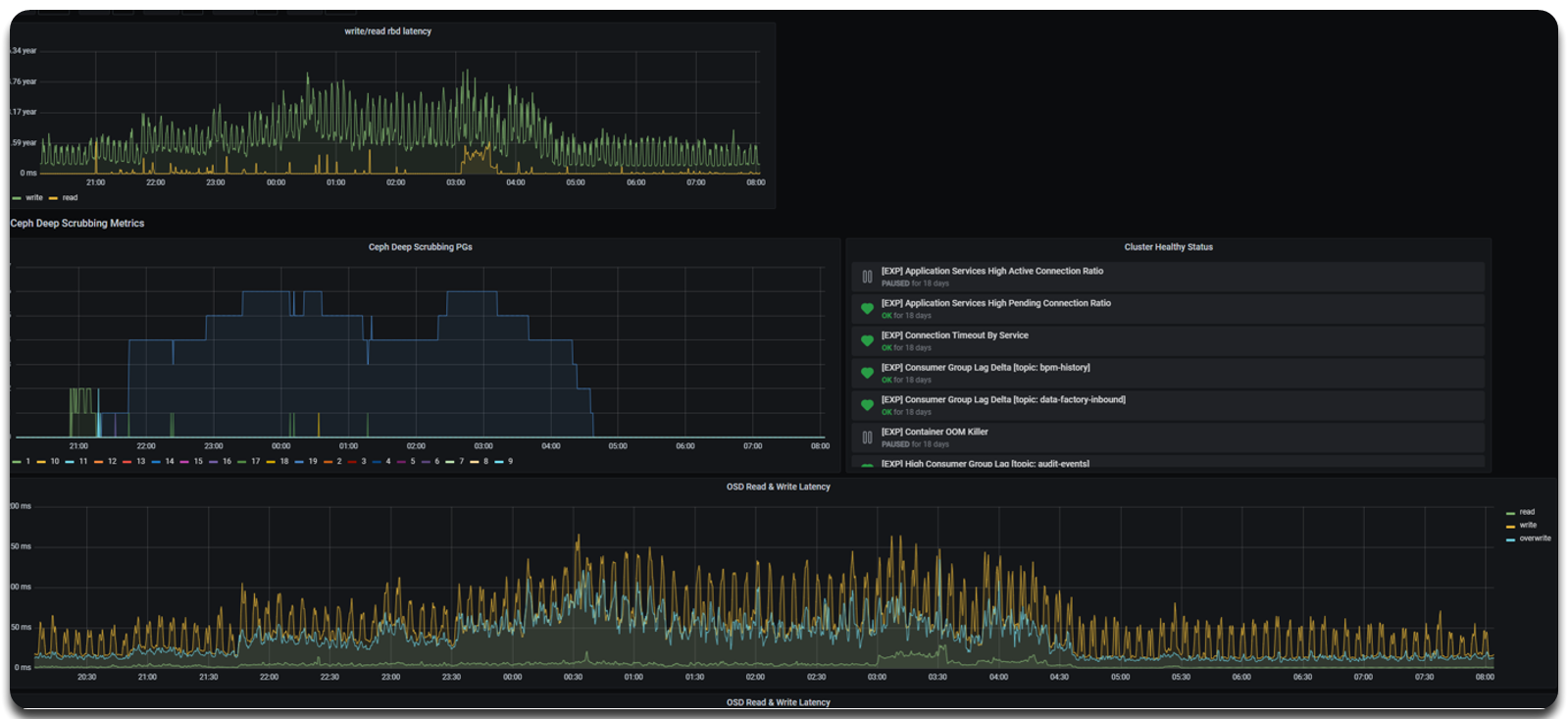
Use the Grafana Dashboard — specifically the Ceph & PostgreSQL Deep Scrubbing Dashboard — to visualize scrubbing activities and OSD performance.
The dashboard shows:
-
Number of PGs undergoing deep scrubbing over time.
-
OSD read/write latency.
-
Current cluster health status.
2.2. Monitoring via Ceph CLI
Use the following commands to track scrubbing progress from the command line:
ceph -s --conf=/var/lib/rook/openshift-storage/openshift-storage.configceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config pg statceph pg --conf=/var/lib/rook/openshift-storage/openshift-storage.config dump pgs | grep -E 'scrub|deep'ceph pg 19.11 query --conf=/var/lib/rook/openshift-storage/openshift-storage.configceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config pg dump pgs | awk '{print $1, $23}' | sort -k2 | column -t3. Stopping deep scrubbing
Sometimes it’s necessary to stop or slow down deep scrubbing — for example, during peak usage or critical transactions. This section describes safe ways to reduce or completely halt the process.
3.1. Soft stop
The recommended method is to reduce the number of concurrent scrubbing processes (osd_max_scrubs) and allow ongoing scrubs to complete naturally. The minimum safe value is 1.
osd_max_scrubs to 1ceph config --conf=/var/lib/rook/openshift-storage/openshift-storage.config set osd osd_max_scrubs 13.2. Force stop
In extreme cases — such as severe performance degradation or blocked I/O — you can stop deep scrubbing immediately by restarting OSDs with PGs in the scrubbing+deep state. Use this approach only when absolutely necessary.
-
Identify PGs currently undergoing deep scrubbing:
ceph pg --conf=/var/lib/rook/openshift-storage/openshift-storage.config dump pgs | grep -E 'scrub|deep'Example output19.11 554 0 0 0 0 72797490 0 0 854 854 active+clean+scrubbing+deep 2025-04-03T07:03:00.295292+0000 2326'7347 2326:18658 [0,2,1] 0 [0,2,1] 0 2263'7328 2025-04-03T07:03:00.295251+0000 2136'4471 2025-03-31T07:38:49.421946+0000 0Table 1. Field reference for ceph pg dump pgsoutputField Description 19.11PG ID — unique Placement Group identifier in
pool_id.pg_numformat.active+clean+scrubbing+deepPG Status — shows PG is active, clean, and currently being deep scrubbed.
[0,2,1]Acting Set — list of OSDs serving the PG; first is the primary OSD.
0Primary OSD index — index in the Acting Set indicating which OSD is primary.
2025-04-03T07:03:00.295251+0000deep_scrub_stamp — timestamp of the last deep scrub for the PG.
-
Delete the relevant OSD pod using OpenShift UI or CLI:
oc delete pod rook-ceph-osd-0-example -n openshift-storage
| Restarting the pod stops active scrubbing on that OSD and triggers PG recovery/rebalancing. Use this option only if no alternatives exist. |