Обслуговування Ceph-кластера та суміжних процесів
| 🌐 Цей документ доступний українською та англійською мовами. Використовуйте перемикач у правому верхньому куті, щоб змінити версію. |
Платформа містить компонент openshift-storage, що розгортає та керує Ceph-кластером за допомогою rook-operator. У цьому документі зібрано перевірені рекомендації щодо обслуговування Ceph-кластера та пов’язаних процесів для забезпечення стабільної роботи та цілісності даних.
1. Ручний запуск та управління процесами Deep Scrubbing
Після встановлення Платформи рекомендовано вимкнути автоматичний запуск deep scrubbing для уникнення впливу на продуктивність у пікові години. Однак періодичне виконання глибокого скрабування є критично важливим для контролю цілісності об’єктів. Цей розділ описує, як повторно активувати deep scrubbing, керувати ним вручну та оптимізувати його виконання.
|
❗ Рекомендовано запускати deep scrubbing вручну регулярно, щонайменше раз на кілька тижнів, залежно від SLA та обсягу критичних даних. Запускайте deep scrubbing у ті періоди, коли у вашому середовищі кластер найменше навантажений — наприклад, уночі в будні або на вихідних, якщо дозволяє графік. Формального вікна обслуговування не потрібно, якщо процес не впливає на критичні сервіси. 📌 Важливо — не допускати накопичення черги PG, які тривалий час залишаються без перевірки.
У кластері з великою кількістю об’єктів і PG може знадобитися запуск щодня з обмеженою кількістю паралельних процесів ( |
1.1. Розблокування та запуск deep scrubbing
Щоб запустити deep scrubbing вручну, спершу необхідно прибрати прапорці nodeep-scrub з усіх пулів, а потім ініціювати відповідні команди для ceph cli з поду rook-operator в OKD-проєкті openshift-storage.
for pool in $(ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls); do
ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool set "$pool" nodeep-scrub false
doneceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls detailceph osd --conf=/var/lib/rook/openshift-storage/openshift-storage.config deep-scrub all# Для конкретного OSD
ceph osd --conf=/var/lib/rook/openshift-storage/openshift-storage.config deep-scrub 0
# Для всіх пулів
for pool in $(ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool ls); do
ceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config osd pool deep-scrub "$pool"
done1.2. Прискорення deep scrubbing при накопиченні черги
У випадках великої кількості PG, які очікують на deep scrubbing, можна прискорити процес:
-
Тимчасово підвищивши кількість паралельних скрабувань.
АБО
-
Розширити вікно обслуговування, запускаючи deep скрабування вручну на ніч у будні дні.
Збільште кількість процесів скрабування на одному OSD в один момент часу, але не більше 4.
ceph config --conf=/var/lib/rook/openshift-storage/openshift-storage.config set osd osd_max_scrubs 4|
Після завершення операції рекомендовано повернути значення ➡️ Детальніше про це описано у розділі Налаштування паралельних процесів scrubbing. |

2. Моніторинг статусу Scrubbing
Цей розділ описує, як перевірити статус скрабування у кластері, відстежувати виконання deep scrubbing та переглядати журналізовану інформацію за PG. Це допомагає своєчасно виявляти проблеми та контролювати цілісність даних.
2.1. Моніторинг через вебінтерфейс Grafana
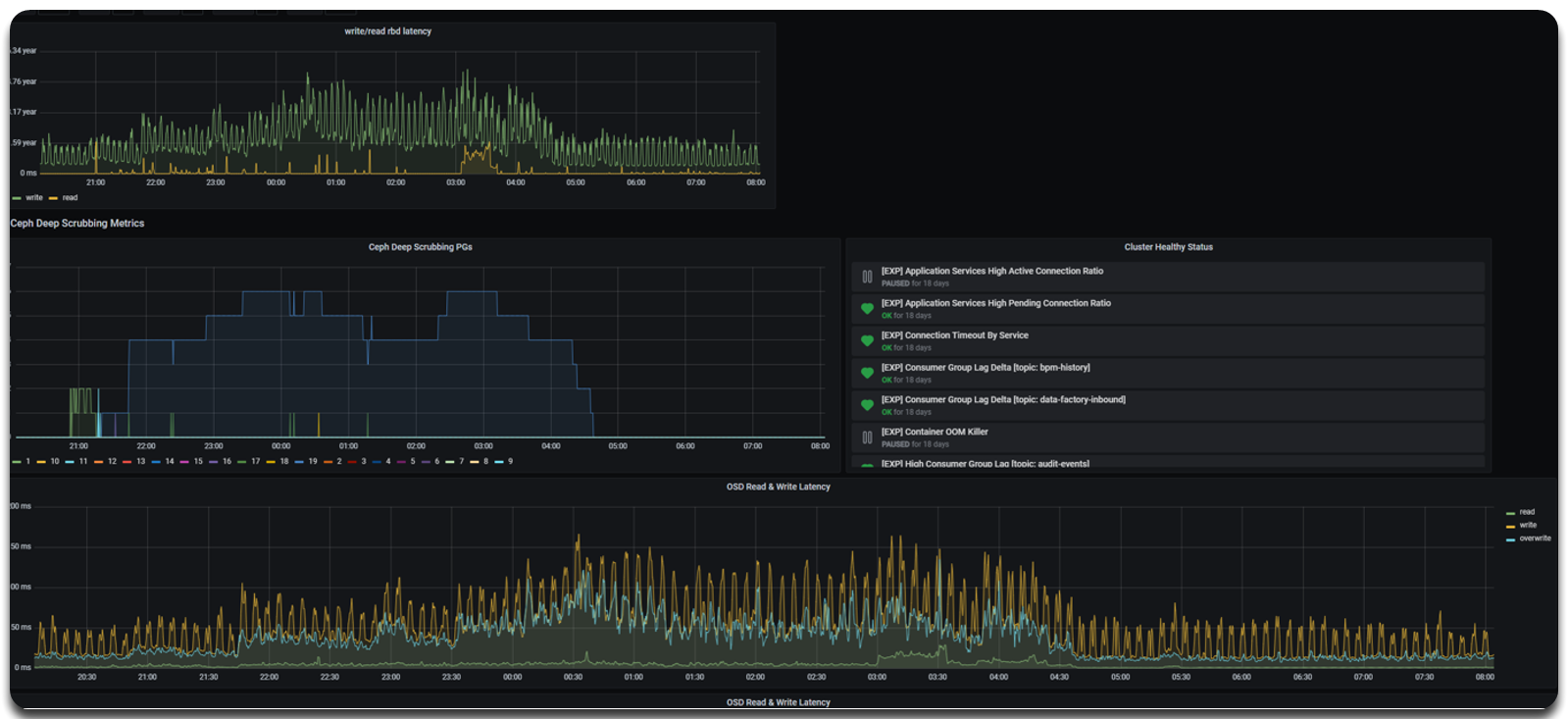
Для зручного спостереження за станом scrubbing і продуктивністю OSD можна скористатися Grafana Dashboard, зокрема дашбордом Ceph & PostgreSQL Deep Scrubbing Dashboard.
Цей дашборд візуалізує:
-
Кількість PG у процесі deep scrubbing — за часовою шкалою;
-
Затримки читання/запису на рівні OSD (OSD Read & Write Latency);
-
Поточний стан кластера — панель Cluster Healthy Status.
Перегляд статусу через Ceph CLI
Ви також можете відстежувати процес скрабування за допомогою Ceph CLI. Нижче подано перелік корисних команд:
ceph -s --conf=/var/lib/rook/openshift-storage/openshift-storage.configceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config pg statceph pg --conf=/var/lib/rook/openshift-storage/openshift-storage.config dump pgs | grep -E 'scrub|deep'ceph pg 19.11 query --conf=/var/lib/rook/openshift-storage/openshift-storage.configceph --conf=/var/lib/rook/openshift-storage/openshift-storage.config pg dump pgs | awk '{print $1, $23}' | sort -k2 | column -t3. Зупинка процесу Deep Scrubbing
Іноді виникає необхідність терміново зупинити або пригальмувати deep scrubbing — наприклад, через пікове навантаження або критичні транзакції в інших сервісах. Цей розділ описує безпечні способи зниження або повної зупинки процесу.
3.1. М’яка зупинка (soft stop)
Рекомендований підхід — зменшити кількість одночасних процесів скрабування (osd_max_scrubs), дозволивши поточним завершитись без запуску нових. Мінімальне значення = 1.
ceph config --conf=/var/lib/rook/openshift-storage/openshift-storage.config set osd osd_max_scrubs 13.2. Примусова зупинка (force stop)
У разі критичної потреби зупинити процес deep scrubbing негайно — наприклад, через деградацію продуктивності або блокування IO — допускається перезапуск OSD, на яких знаходяться PG у статусі scrubbing+deep.
Цей метод є жорстким втручанням і повинен використовуватися лише у виняткових випадках.
-
Визначте PG, для яких виконується deep scrubbing.
ceph pg --conf=/var/lib/rook/openshift-storage/openshift-storage.config dump pgs | grep -E 'scrub|deep'Приклад результату у виводі команди19.11 554 0 0 0 0 72797490 0 0 854 854 active+clean+scrubbing+deep 2025-04-03T07:03:00.295292+0000 2326'7347 2326:18658 [0,2,1] 0 [0,2,1] 0 2263'7328 2025-04-03T07:03:00.295251+0000 2136'4471 2025-03-31T07:38:49.421946+0000 0Таблиця 1. Пояснення ключових полів у виводі команди ceph pg dump pgsЗначення поля Опис 19.11PG ID — унікальний ідентифікатор Placement Group у форматі
pool_id.pg_num.active+clean+scrubbing+deepСтатус PG — вказує, що PG активна, цілісна (
clean) і наразі перебуває в процесі глибокого скрабування (scrubbing+deep).[0,2,1]Acting Set — список OSD, які обслуговують дану PG. Перший у списку — це primary OSD.
0Primary OSD index — позиція в Acting Set, яка визначає, який саме OSD є primary. Наприклад, якщо Acting Set —
[0,2,1]і індекс —0, то primary — цеOSD 0.2025-04-03T07:03:00.295251+0000deep_scrub_stamp — дата та час останнього виконання deep scrubbing для PG.
-
Видаліть відповідний pod OSD через OpenShift UI або CLI.
oc delete pod rook-ceph-osd-0-example -n openshift-storage
| Перезапуск pod призведе до зупинки поточних скрабінг-процесів на відповідному OSD та ініціює recovery/rebalancing PG. Використовуйте лише за відсутності альтернатив. |