Розширення кількості OSD та налаштування ребалансування в Ceph
| 🌐 Цей документ доступний українською та англійською мовами. Використовуйте перемикач у правому верхньому куті, щоб змінити версію. |
Цей документ охоплює сценарії масштабування Ceph-кластера шляхом додавання нових OSD (Object Storage Daemon) та оптимізацію процесу ребалансування для запобігання деградації продуктивності системи.
| Рекомендовано налаштувати Grafana-алерт на спрацювання при заповненні понад 75% дискового простору, щоб завчасно масштабувати кластер. |
1. Розширення кількості OSD
У разі нестачі дискового простору у Ceph-кластері необхідно додати нові PVC та відповідно розширити кількість OSD (Object Storage Daemon) шляхом оновлення ресурсу StorageCluster CR.
1.1. Додавання нових OSD через StorageCluster CR
-
Перейдіть до редагування ресурсу
StorageCluster CRу просторі іменopenshift-storage.Редагування ресурсуStorageCluster CRoc edit StorageCluster -n openshift-storage ocs-storagecluster -
Знайдіть секцію
storage.storageClassDeviceSetsта змініть конфігурацію, щоб додати нові OSD. Для цього збільште параметр count на +1 групу OSD або більше, враховуючи залежність на кількість реплік (replica) та розмір сховища (storage). У прикладі нижче додається одна група з трьома репліками розміром512Gi.Ресурс StorageCluster. Конфігурація storage.storageClassDeviceSetsstorage: storageClassDeviceSets: - name: ocs-deviceset-gp3-csi count: 2 # було 1 — збільшуємо на +1 (1) replica: 3 (2) resources: limits: cpu: "4" memory: 16Gi requests: cpu: "2" memory: 8Gi volumeClaimTemplates: - metadata: name: data spec: resources: requests: storage: 512Gi (3) storageClassName: gp3-csi volumeMode: Block accessModes: - ReadWriteOnce
| 1 | count — кількість груп OSD, що буде розгорнута. Збільшення count на +1 додає нову групу з OSD, відповідно до вказаної кількості реплік. |
| 2 | replica — кількість OSD у кожній групі. Наприклад, replica: 3 означає, що кожна група складається з трьох OSD. |
| 3 | storage — розмір кожного PVC у складі OSD. У прикладі використовується 512Gi для кожної репліки. |
| Перед масштабуванням обов’язково перевірте актуальні значення Capacity наявних PVC. Усі нові OSD повинні мати такий самий розмір, щоб уникнути дисбалансу в Ceph-кластері. |
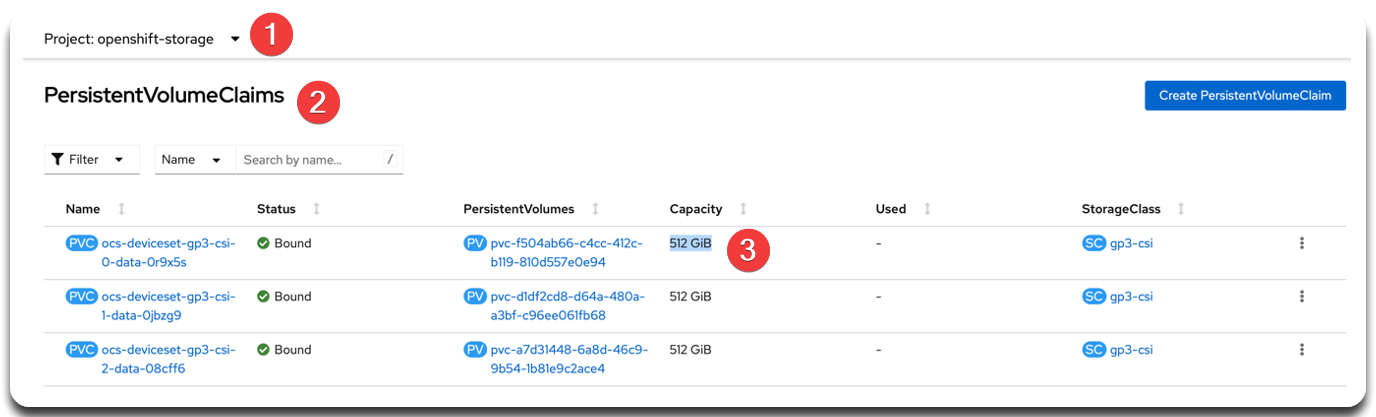
1.2. Перевірка результату
Перевірте результат за допомогою наступних команд:
-
Перевірте статус Ceph-кластера:
ceph -s --conf=/var/lib/rook/openshift-storage/openshift-storage.configЦя команда виводить загальний стан Ceph-кластера, включно з кількістю OSD, станом моніторів, PG та станом реплікації.
-
Переконайтеся, що нові OSD додано:
ceph osd tree --conf=/var/lib/rook/openshift-storage/openshift-storage.configЦя команда показує ієрархію OSD у кластері. Тут можна побачити нові OSD, що були додані, а також їхній статус та приналежність до хостів.
2. Налаштування та оптимізація ребалансування
Після додавання або видалення OSD у Ceph автоматично запускається процес ребалансування (rebalancing) — перенесення об’єктів між OSD для рівномірного розподілу навантаження.
Цей процес може бути ресурсомістким і вплинути на загальну продуктивність кластера. Нижче наведено параметри для налаштування цього процесу — для сценаріїв зменшення навантаження, або пришвидшення.
2.1. Зменшення навантаження при ребалансуванні
Цей варіант підходить для сценаріїв, коли важливо зберегти стабільну продуктивність під час робочого часу.
-
Обмежте кількість паралельних потоків (
backfills).ceph config set osd osd_max_backfills 1 --conf=/var/lib/rook/openshift-storage/openshift-storage.config ceph config set osd osd_recovery_max_active 1 --conf=/var/lib/rook/openshift-storage/openshift-storage.configЦі параметри зменшують кількість одночасних потоків перенесення даних (
backfills/recovery), що знижує навантаження на OSD під час ребалансування. -
Зменште швидкість бекапів шляхом додавання пауз між ними.
ceph config set osd osd_recovery_sleep 0.1 --conf=/var/lib/rook/openshift-storage/openshift-storage.configЦей параметр додає паузу (
sleep) у 0.1 секунди між операціямиrecovery, зменшуючи навантаження на диск і CPU.
2.2. Прискорення ребалансування (рекомендовано у вікно обслуговування)
У періоди мінімального навантаження (наприклад, уночі або на вихідних) можна прискорити процес розподілу, дозволивши більше одночасних потоків backfills.
ceph config set osd osd_max_backfills 4 --conf=/var/lib/rook/openshift-storage/openshift-storage.config
ceph config set osd osd_recovery_max_active 4 --conf=/var/lib/rook/openshift-storage/openshift-storage.configЦі параметри дозволяють запускати більше паралельних потоків backfills і recovery, прискорюючи ребалансування даних. Застосовуйте лише у періоди низького навантаження, наприклад уночі або під час вікна обслуговування.
2.3. Моніторинг процесу ребалансування
Використовуйте наведені нижче команди для контролю прогресу ребалансування та поточного стану PG.
ceph -s --conf=/var/lib/rook/openshift-storage/openshift-storage.configВиводить поточний стан Ceph, включаючи статус recovery, backfill, degraded PG тощо.
ceph pg stat --conf=/var/lib/rook/openshift-storage/openshift-storage.config
Показує деталізовану статистику по Placement Groups, включаючи статуси active, clean, backfilling, recovering.
Якщо після масштабування або видалення OSD кластер довго перебуває у стані degraded, перевірте наявність неактивних PG або дискових помилок у логах Ceph.
|