Отримання сутностей у Фабриці даних масивом: Batch Read entities from data factory
1. Загальна інформація
Інтеграційне розширення Batch Read entities from data factory дозволяє налаштовувати читання даних із таблиці (сутності) масивом у бізнес-процесі. Це розширення допомагає автоматизувати процеси отримання списків сутностей за їх ідентифікаторами, забезпечуючи належне оброблення даних та передачу їх до наступних етапів бізнес-процесу. Розширення додає різні властивості до сервісного завдання (Service Task).
| Назва | Пояснення |
|---|---|
Бізнес-назва інтеграційного розширення |
Batch Read entities from data factory |
Службова назва інтеграційного розширення |
|
Назва файлу у бібліотеці розширень |
dataFactoryConnectorBatchReadDelegate.json |
2. Перед початком
|
Якщо ви використовуєте функціональність Кабінету адміністратора регламентів для розробки реєстру, вам не потрібно встановлювати типові розширення, додаткові зовнішні застосунки та плагіни. Портал містить усе необхідне вбудоване з коробки. При моделюванні бізнес-процесів із використанням сторонніх застосунків, важливо інтегрувати каталог типових розширень з нашого репозиторію. Завітайте до business-process-modeler-extensions, щоб завантажити необхідні файли. Наприклад, для таких інструментів, як Camunda Modeler, у вашій теці /element-templates мають бути включені відповідні JSON-файли. Для детальних інструкцій, будь ласка, перегляньте Встановлення типових розширень. |
3. Налаштування
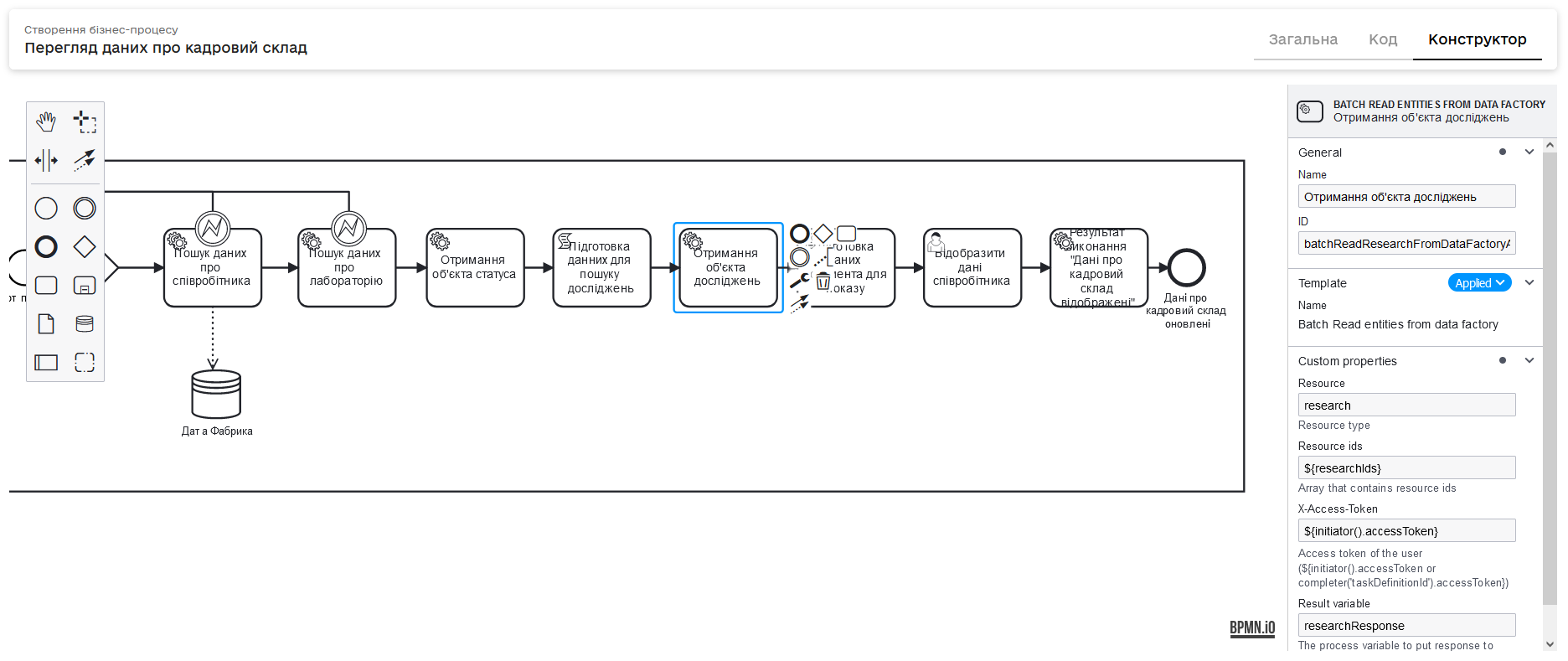
Делегат Batch Read entities from data factory призначений для використання у сервісних завданнях (Service Task) бізнес-процесу. Він дозволяє налаштувати автоматичне отримання даних із таблиці (сутності) масивом з різними параметрами.
3.1. Налаштування завдання
-
Створіть завдання типу Service Task у вашому бізнес-процесі.
-
Назвіть завдання, наприклад,
Перегляд даних про кадровий склад. -
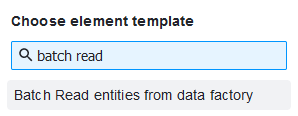
Застосуйте шаблон делегата, обравши Batch Read entities from data factory зі списку в налаштуваннях завдання.
Завдання приймає вхідні дані з попереднього завдання та передає результат до наступного етапу процесу.
3.2. Налаштування делегата
- Resource
-
У полі Resource вкажіть ресурс, з якого потрібно отримати дані.
- Resource ids
-
У полі Resource ids передайте масив ідентифікаторів ресурсів, наприклад,
${researchIds}.researchIdsможна отримати зі скрипту, наприклад, наступним чином:def researchesIds = response.responseBody.prop("researches").elements().stream() .map(objId -> objId.value()) .collect() set_transient_variable("researchIds", researchesIds)Цей скрипт обробляє інформацію й отримує масив даних по всім об’єктам досліджень співробітника, зберігаючи ідентифікатори сутностей у змінній
researchIds. - X-Access-Token
-
У полі X-Access-Token зазначте токен доступу користувача, під яким виконується операція. Наприклад:
${initiator().accessToken}Або використайте токен виконавця останнього користувацького завдання:
${completer('previous user task ID').accessToken}-
completer()— назва JUEL-функції. -
'previous user task ID'— ID попередньої задачі користувача. -
accessToken— метод, який передає JWT-токен користувача.
-
- Result variable
-
У полі Result variable вкажіть назву змінної, в яку необхідно записати результат. Наприклад,
researchResponse.
|
У результаті виконання делегата повертається масив сутностей у наступному форматі: Приклад відповіді
|
4. Приклад
Ось приклад, який показує, як відповідний делегат використовується у бізнес-процесі: